nvm可以管理node版本,使用homebrew安装nvm后,nvm -v查看版本提示
zsh: command not found: nvm
解决方案
1.使用homebrew安装nvm
1 | brew install nvm |
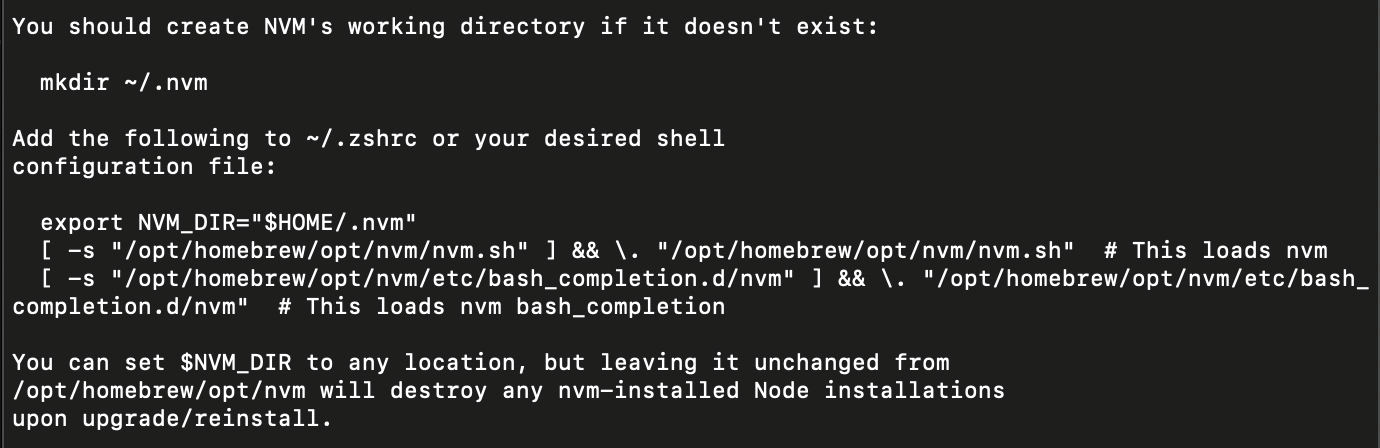
2.如果~/.nvm不存在,创建文件夹
1 | mkdir ~/.nvm |
3.配置环境变量
1 | vim ~/.zshrc |
注意:通过homebrew安装的nvm,环境变量里配置的路径跟别的不太一样。
1 | source ~/.zshrc |
附:终端提示的操作方法
1 | <script src="https://cdn.bootcss.com/vConsole/3.2.2/vconsole.min.js"></script> |
https://www.npmjs.com/package/vconsole
display: -webkit-box;子元素之间有间距1 | display: -webkit-box; |
父元素设置font-size: 0; 子视图重新设置font-size
1 | <div>test</div> |
需要设置 font-size
1 | overflow: hidden; |
更换引入方式,使用 import
1 | // 原 |
1 | -webkit-tap-highlight-color: rgba(0, 0, 0, 0); |
ios点击出现灰色背景_ios 点击元素出现 背景-CSDN博客
vant 版本为2.x.x
按需手动导入样式文件,以 List 为例:
1 | import 'vant/lib/list/style'; |
https://vant-ui.github.io/vant/v2/#/zh-CN/list
postcss-pxtorem
可以在不期望转换的px后紧跟/* ignore */
1 | @media screen and (min-width 640px/* ignore */) { |
弹窗、提示等 z-index 收敛到一个文件里方便维护
父视图不想设置宽度(写死宽度不太聪明的样子),可以设置 min-width: 0;或 width: 0;
flex弹性布局 子元素内容超出盒子容器宽度问题_flex布局子元素超过页面-CSDN博客
需要设置 position: relative
1 | margin-top: -40px; |
使用小程序 API 时注意判断版本,例如隐藏页面左上角返回按钮 backButtonHide 最低版本 3.660.1
控制台输入命令等1
2
3location.reload()
location.href
window.pageData
nvm可以管理node版本,使用homebrew安装nvm后,nvm -v查看版本提示
zsh: command not found: nvm
1 | brew install nvm |
1 | mkdir ~/.nvm |
1 | vim ~/.zshrc |
注意:通过homebrew安装的nvm,环境变量里配置的路径跟别的不太一样。
1 | source ~/.zshrc |
附:终端提示的操作方法
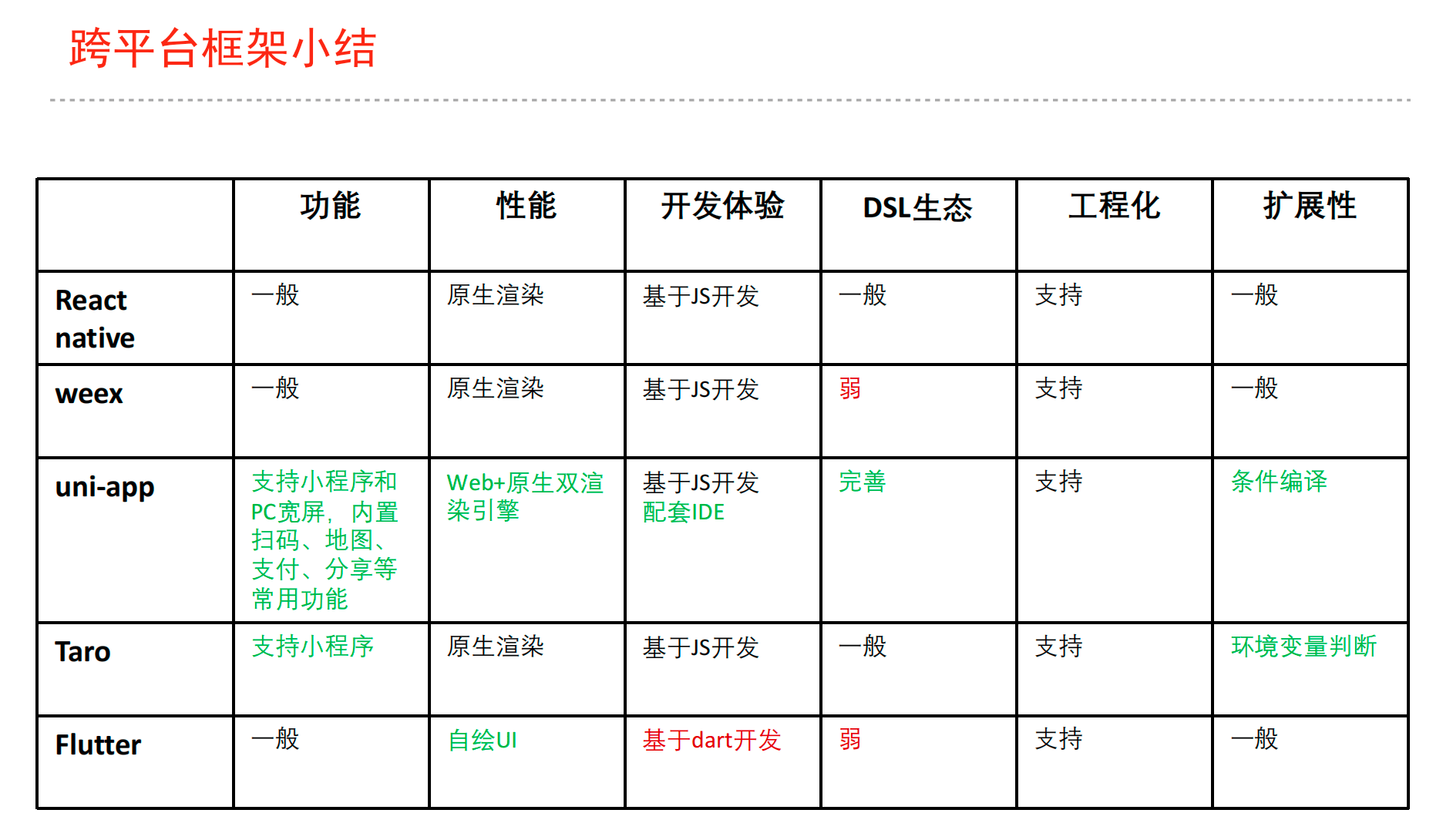
uni-app 产品负责人、DCloud CTO

1.提升人效
2.抹平差异

基于WebView的增强
1.ionic
2.CORDOVA Hybrid框架
3.SONIC 客户端预加载WebView资源
4.小程序(WebView)
5.离线包方案App厂商对Web做的离线包方案
特点:
1.基于WebView渲染,补充了一些原生能力的增强
2.开发生态基于 Web 前端生态
3.想方设法增强Web的用户体验
基于DSL的Native增强
(DSL:Domain-specific language 领域特定语言是专门针对特定应用程序领域的计算机语言)
1.DinamicX 手淘无障碍框架
2.Tangram 阿里七巧板
3.Jasonette
4.DreamBox
5.MTFlexbox 美团
MTFlexbox首先定义一份跨平台统一的DSL布局描述文件,前端通过“所见即所得”的编辑器编辑产生布局,客户端下载布局文件后,根据布局中的描述绑定JSON数据,并最终完成视图的渲染。
特点:
1.开发生态基于Native,框架设计参考WebView的一些特性
2.自定义DSL来实现跨端与动态化
设计的像React Native
Kotlin MultiplatformKKM Kotlin Multiplatform Mobile 代码共享
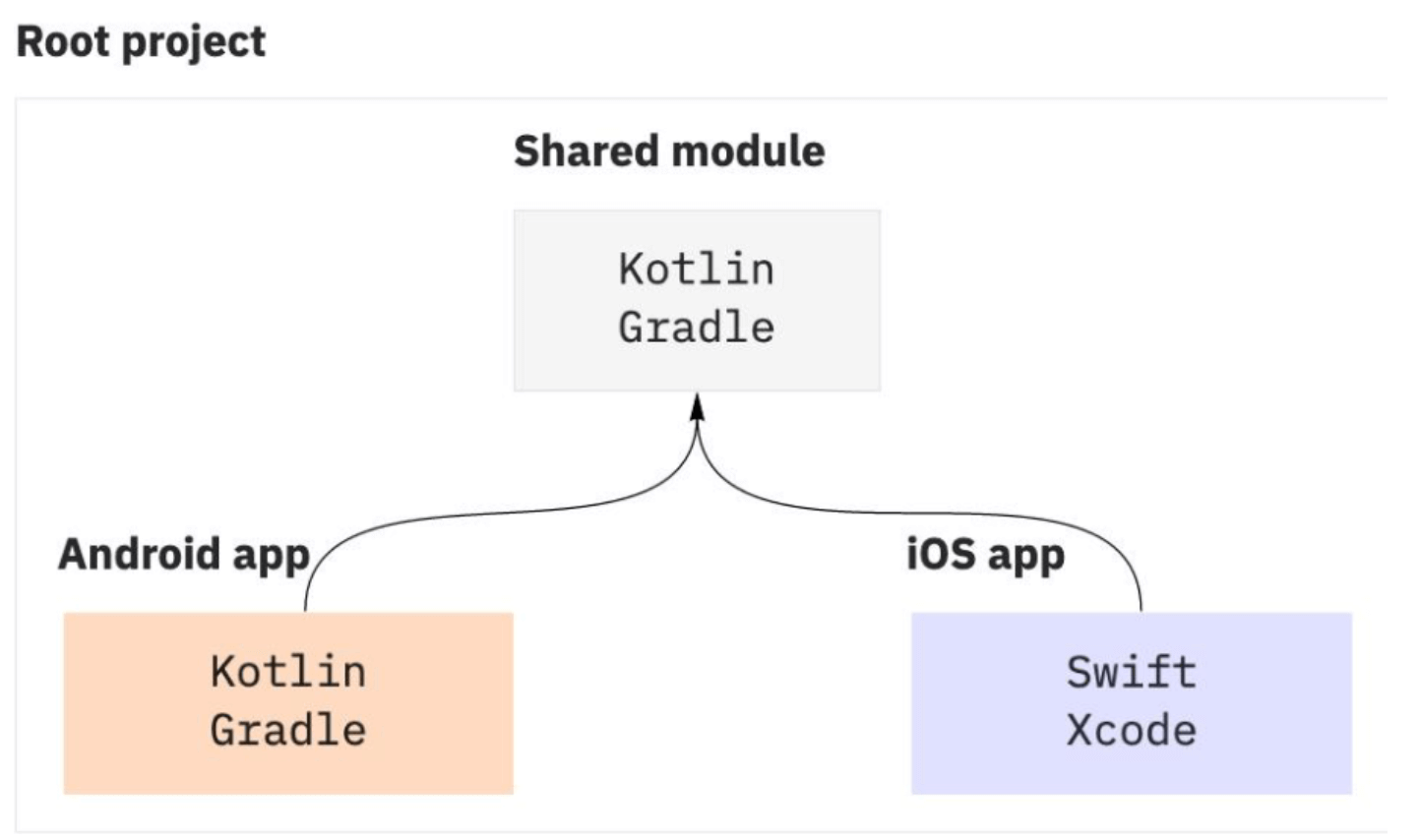
跨端代码 Shared module
壳工程 Android/iOS App
基于GPL的Native增强
(GPL: General Public License 通用公共许可证)
1.Native Widget 原生渲染组件
React Native / Hippy 1.0 / Weex 1.0
2.自绘引擎 Flutter
3.基于Flutter的自绘框架
1 | webF`,`Kraken`, `Kun`, `Skyline |
4.基于系统图形库(Skia(Google出的图形处理引擎) / OpenGL(开放图形库) / Vulkan / Metal)的自绘框架
TDF(Tencent Dynamic Framework), Hippy 3.0, Weex 2.0, MagicBrash, Waft(WebAssembly Framework for Things)
Waft(WebAssembly Framework for Things)
AloT的尝试
1.Android App: 运存太低,性能受限
2.Waft
Waft构成:
1.脚本引擎:WebAssembly
2.渲染引擎:Skia封装
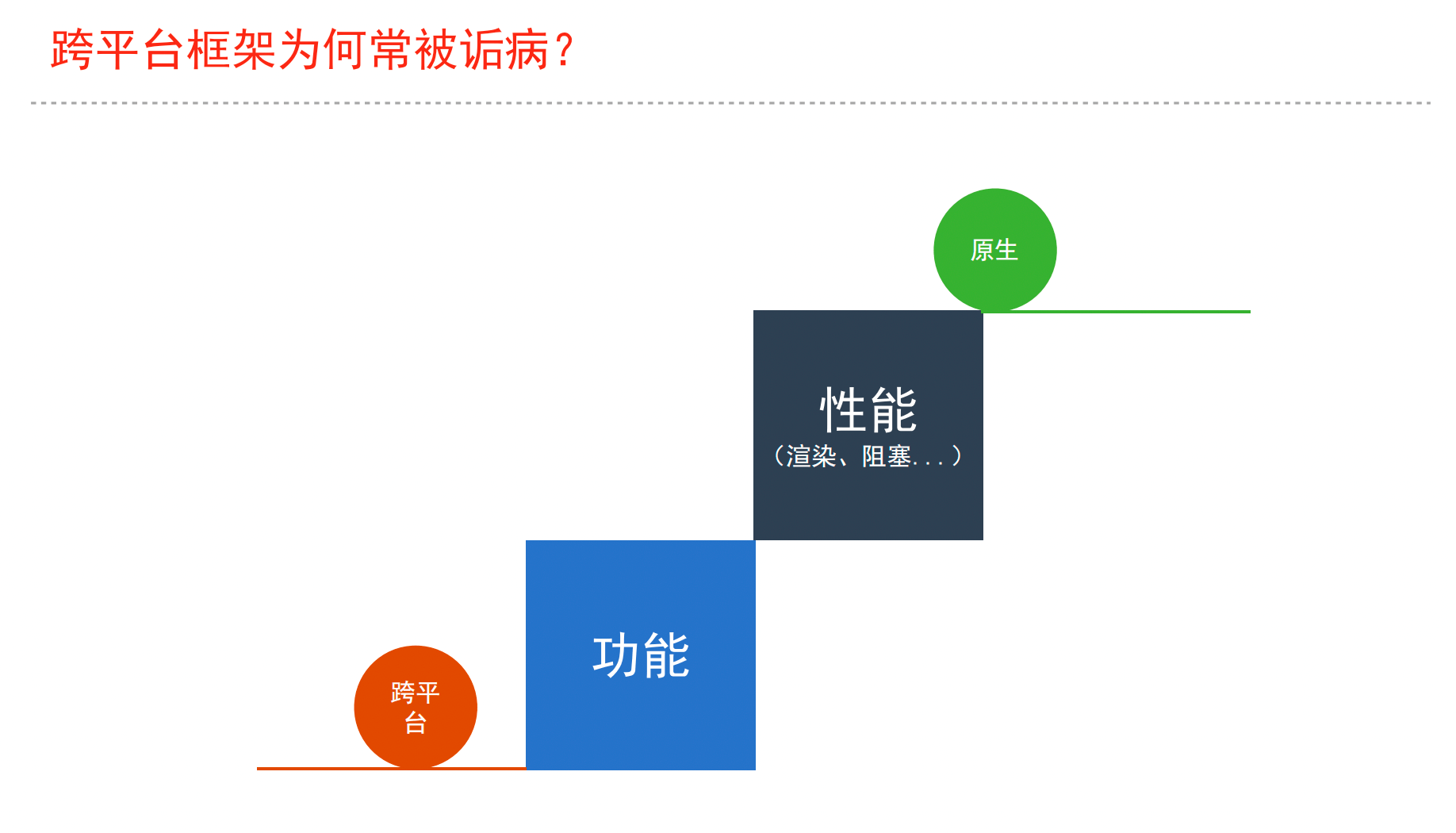
WebView的增强DSL的Native增强GPL的Native增强Android)OC运行时动态化特性(iOS)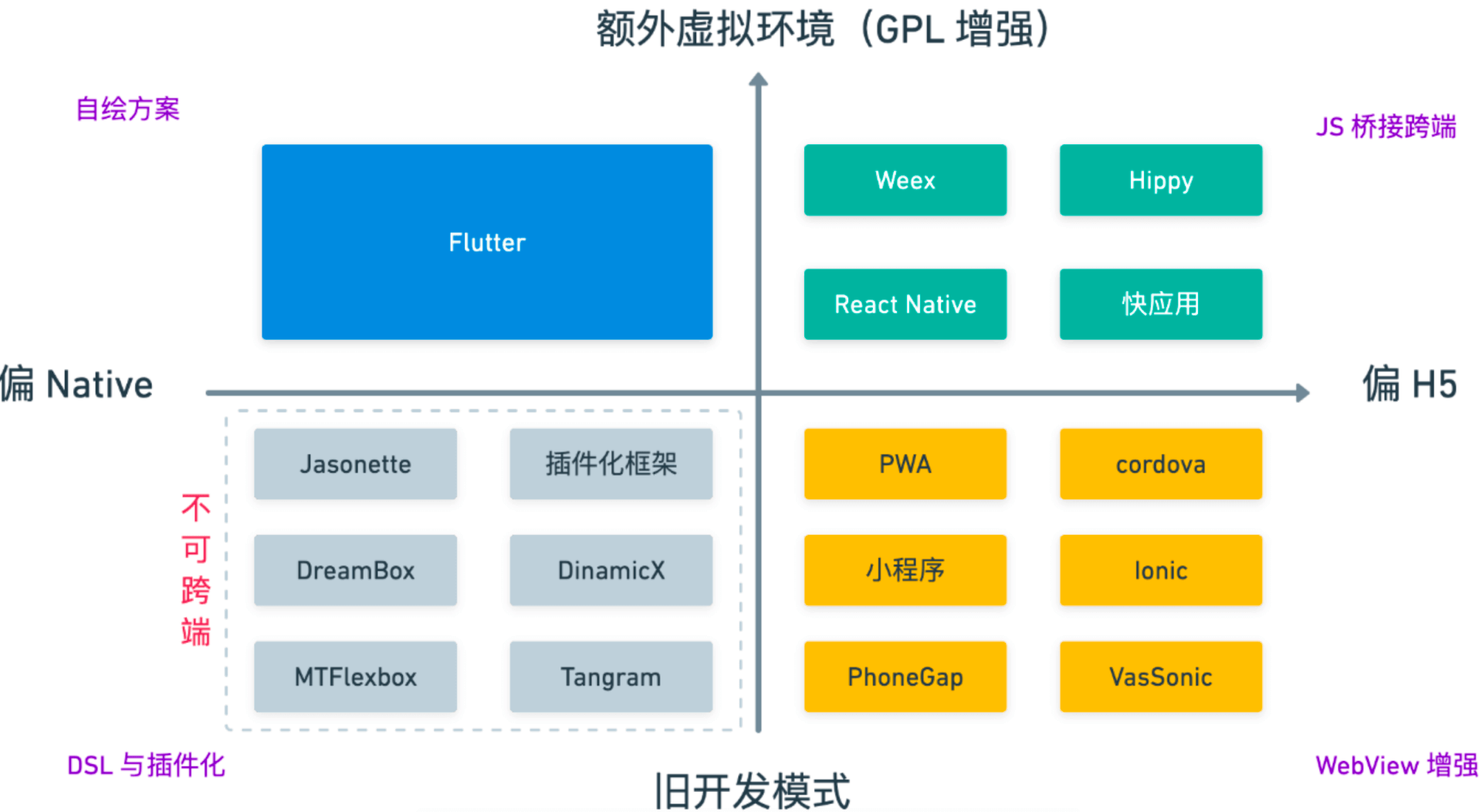
JS引擎:双引擎(JSCore + V8)、单引擎(Hermes)、单引擎(QuickJS)、单引擎(自研JS引擎)DartVM:利用Flutter EngineWARM:需要设计DSL和实现渲染引擎Flutter EngineSkia / OpenGL / Vulkun / MetalDebugger:一种可以让 JavaScript Runtime 进行中断,并可以实时查看内部运行状态的应用
调试协议:
CDP: Chrome DevTools ProtocolDAP: Debug Adapter Protocol
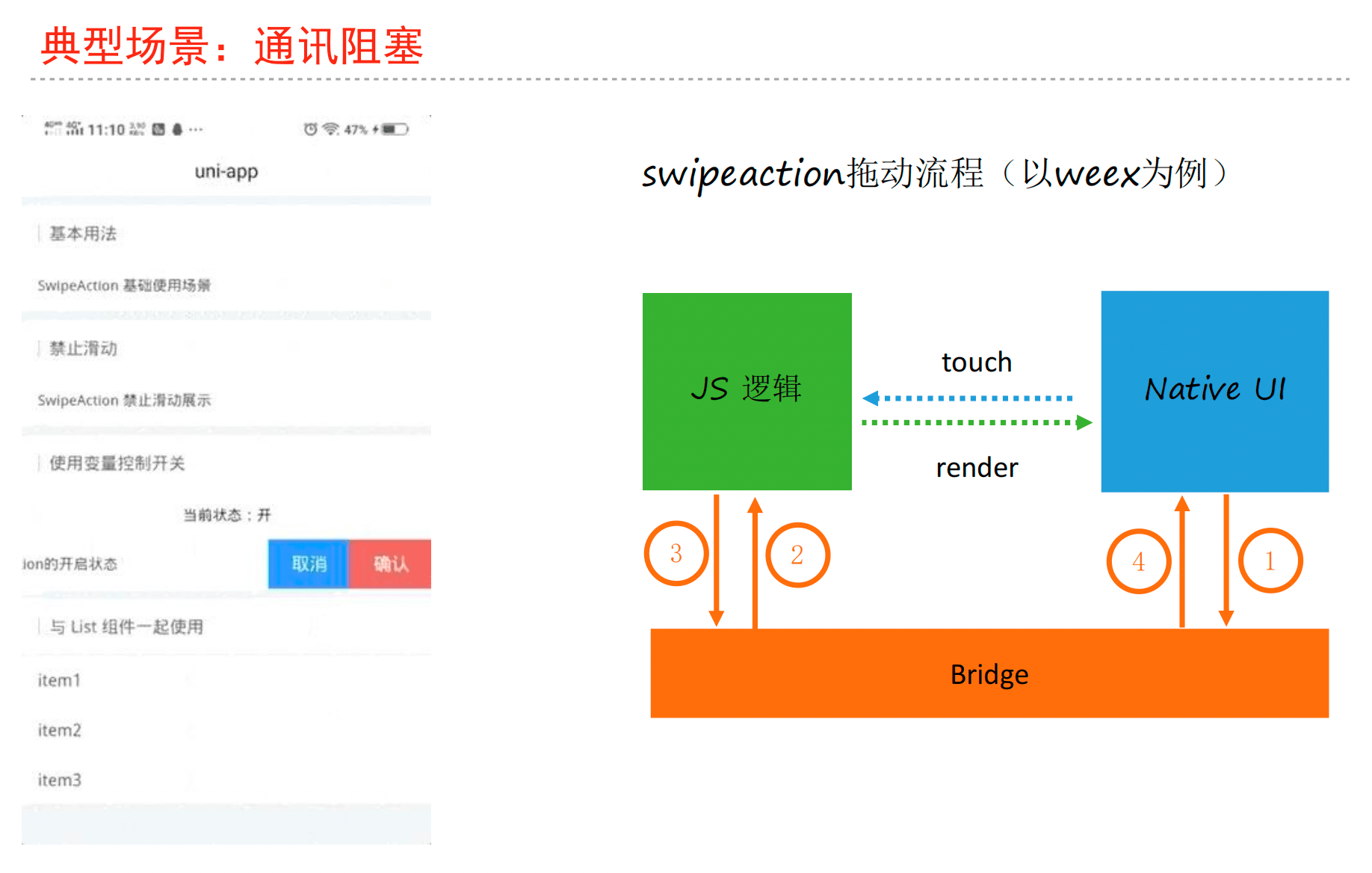

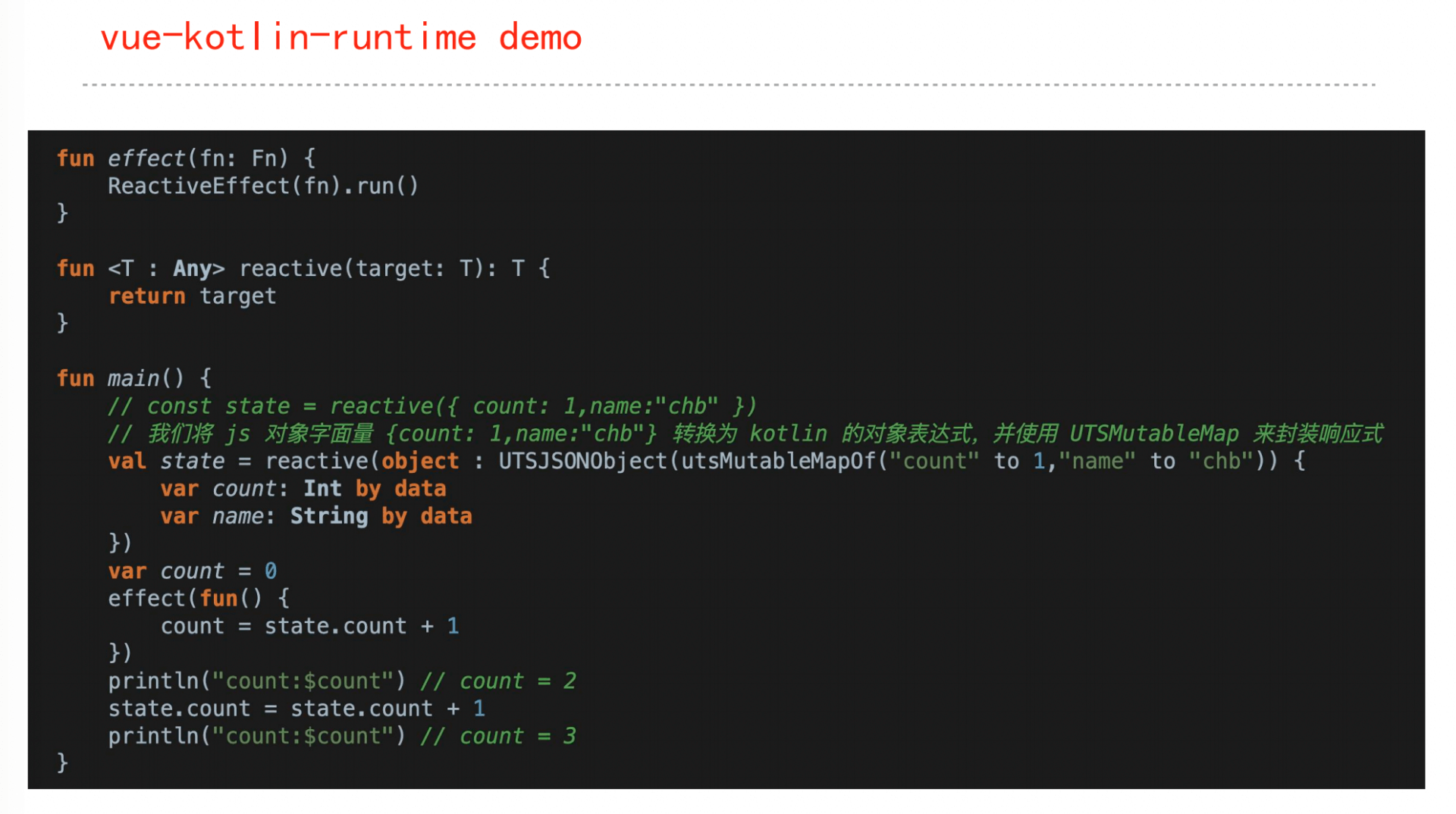
UTS官方文档:https://uniapp.dcloud.net.cn/tutorial/syntax-uts.html
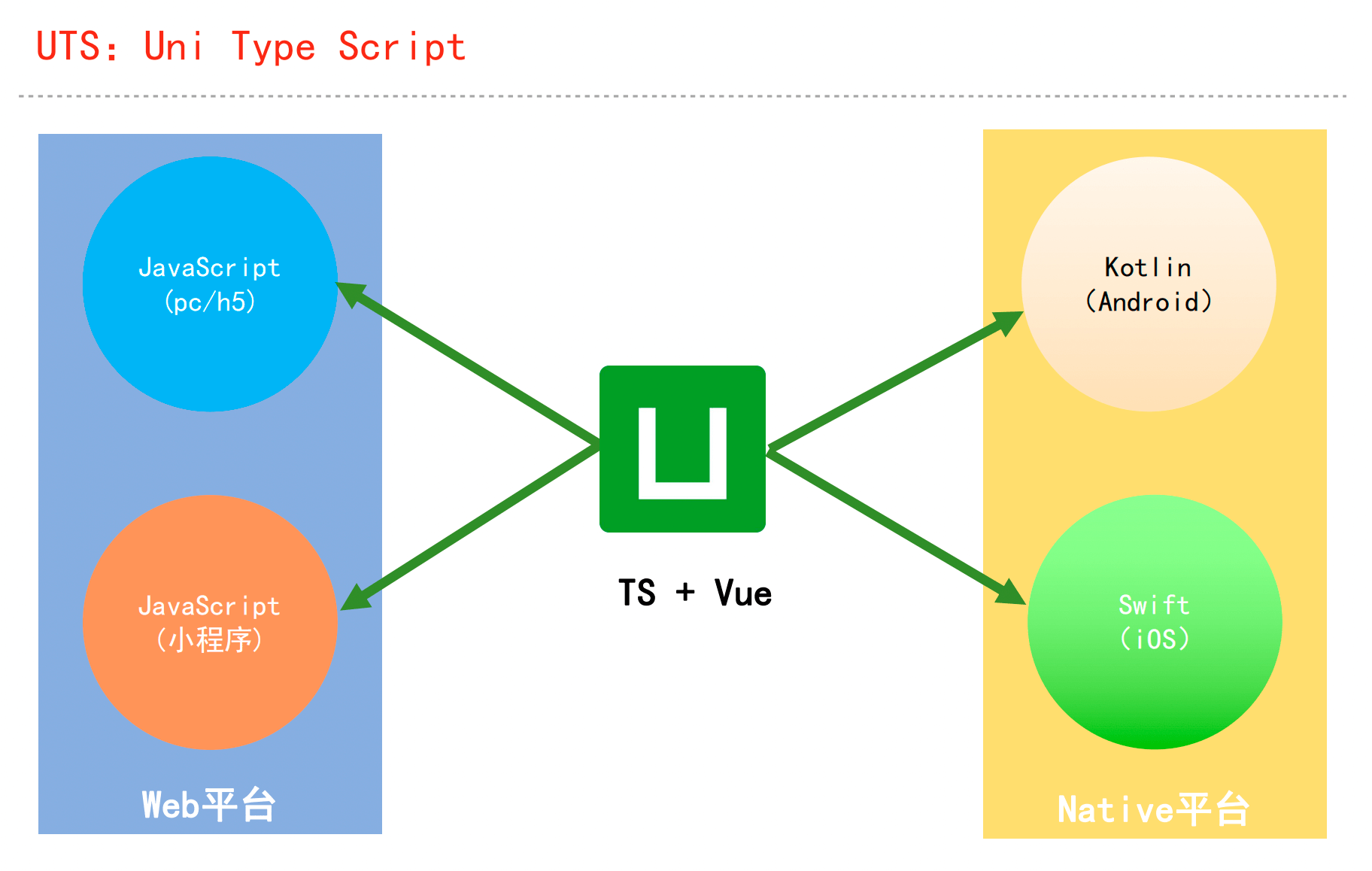
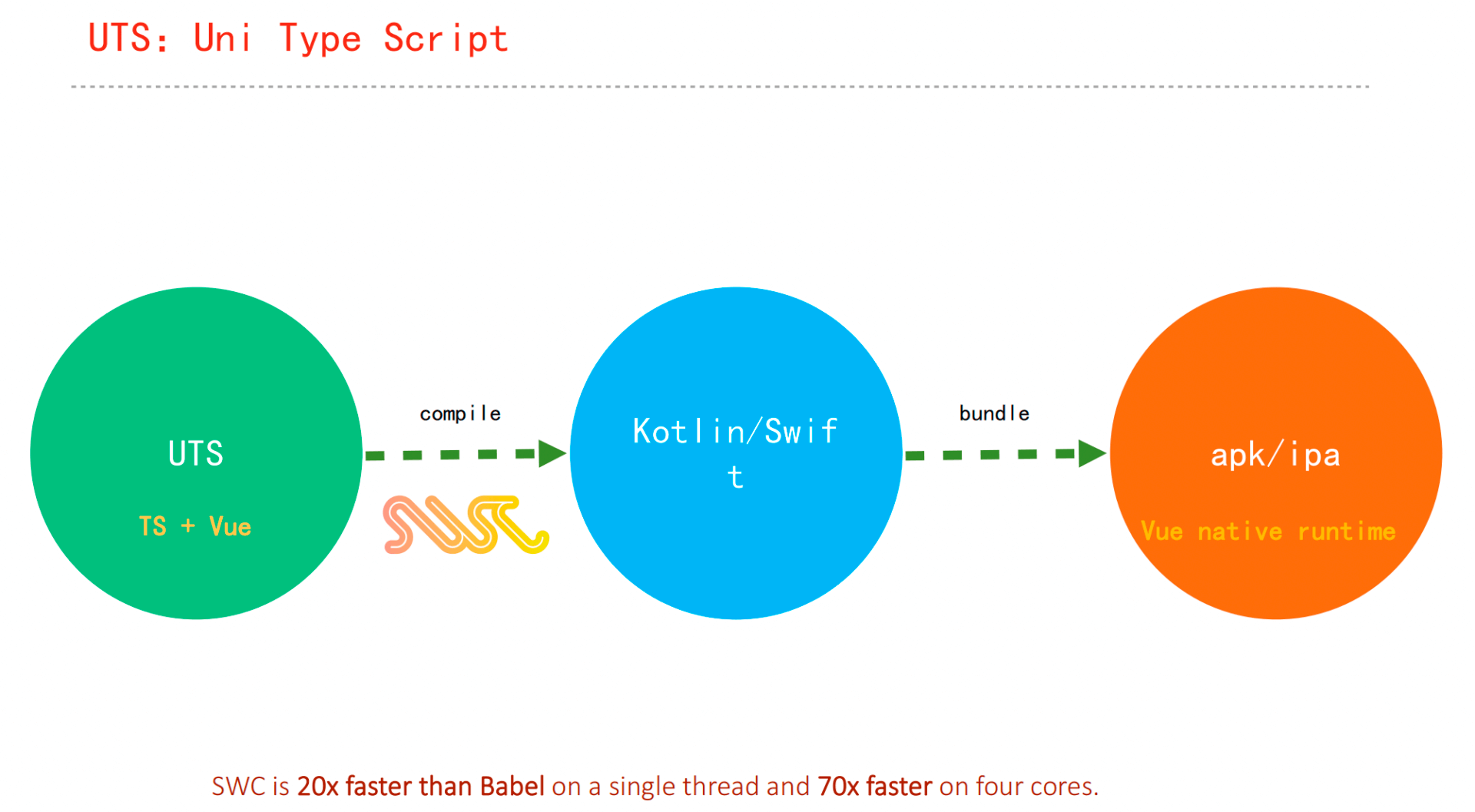
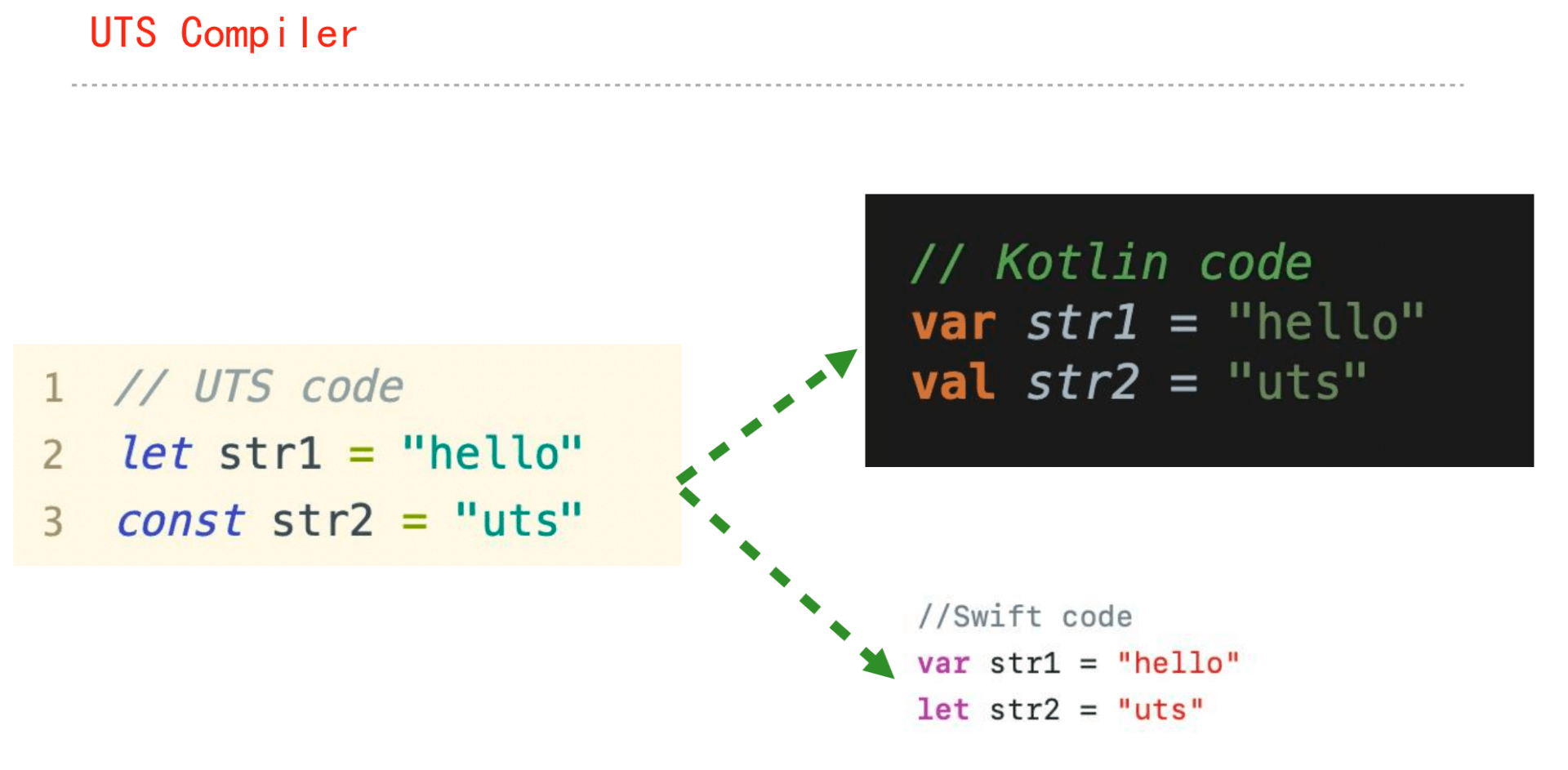
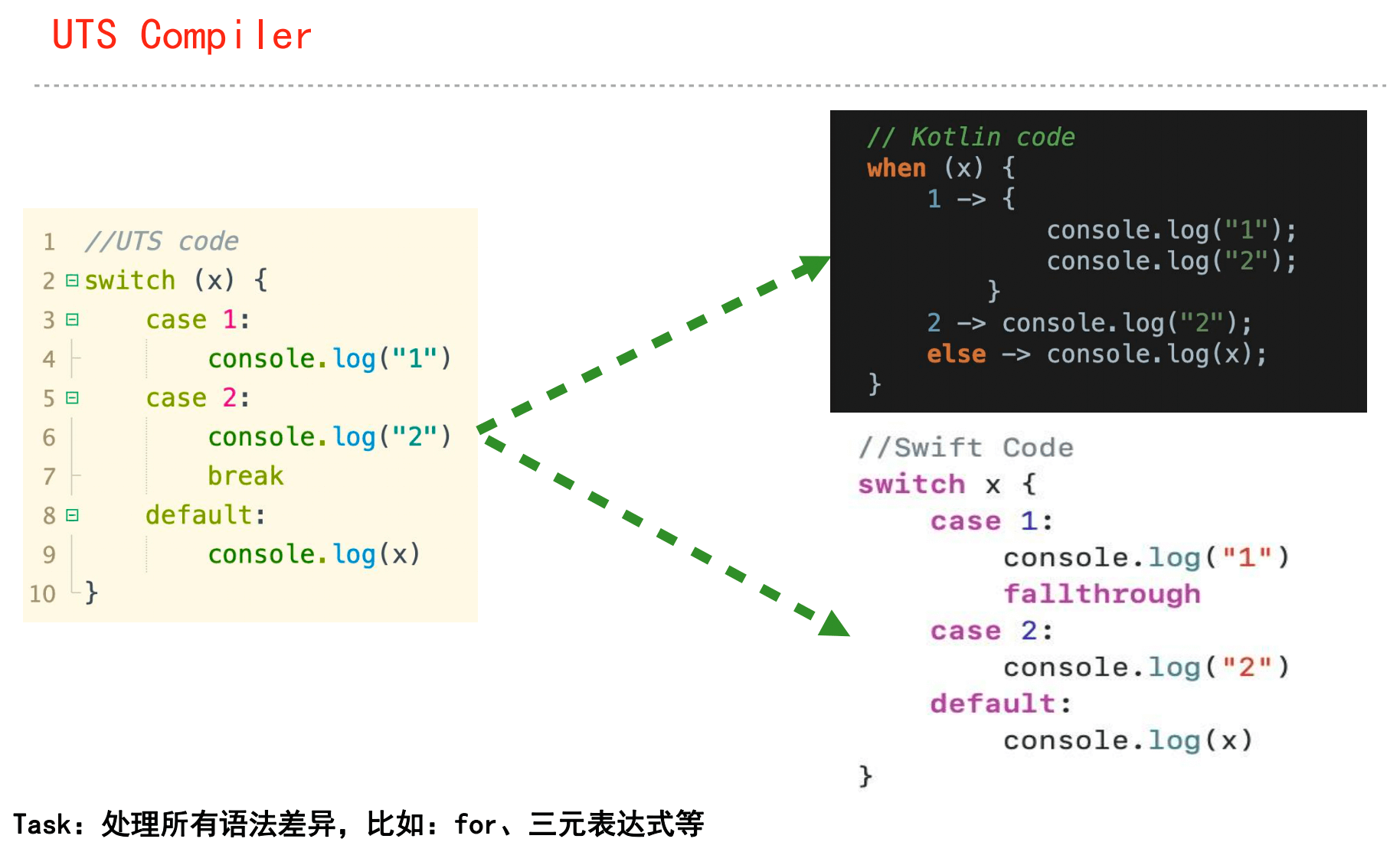

框架设计就是追求取舍平衡的过程
uts是对ts的定制,有删有增有重定义


改善前后端协同,赋能前端,加速业务
协作模式改变,更少代码,更高效率
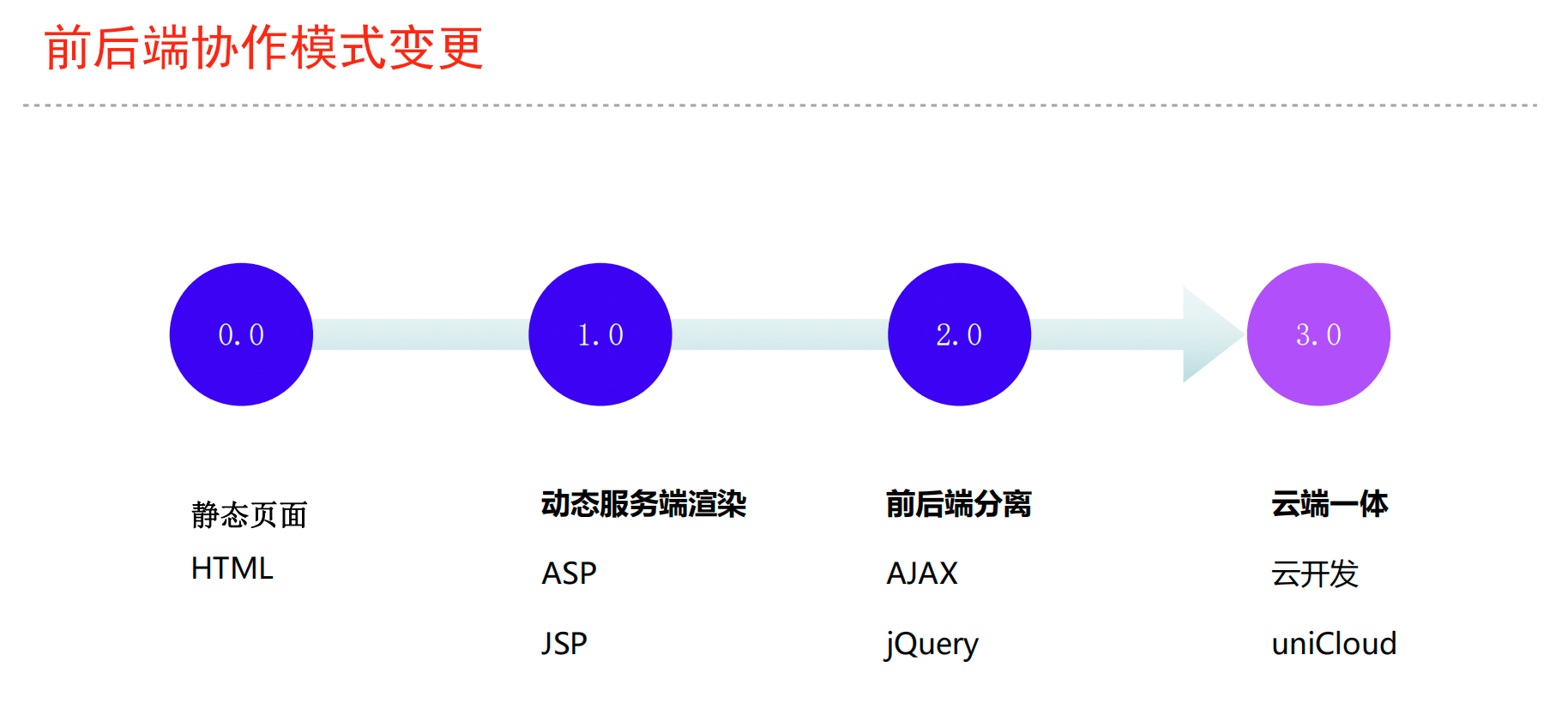
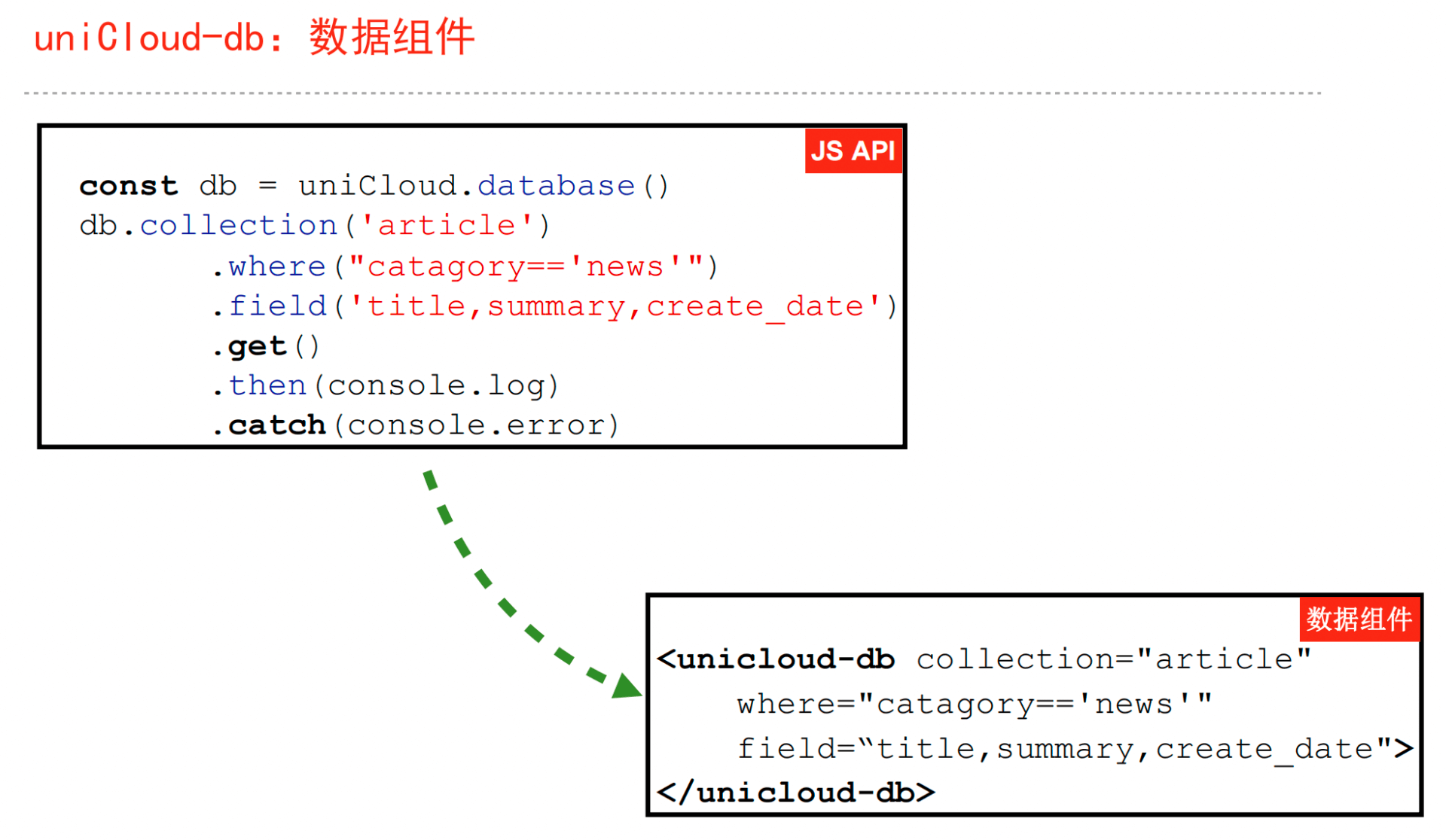


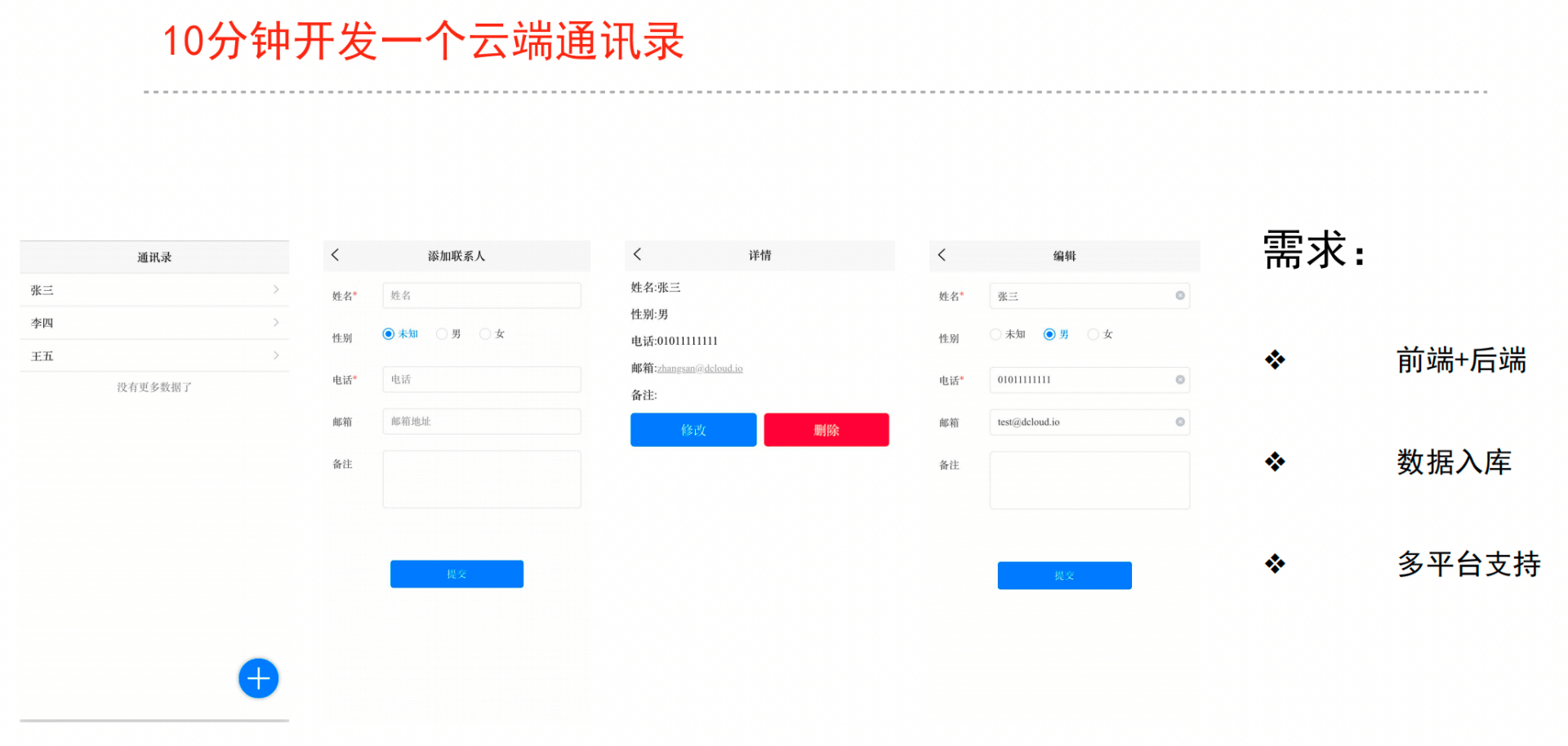
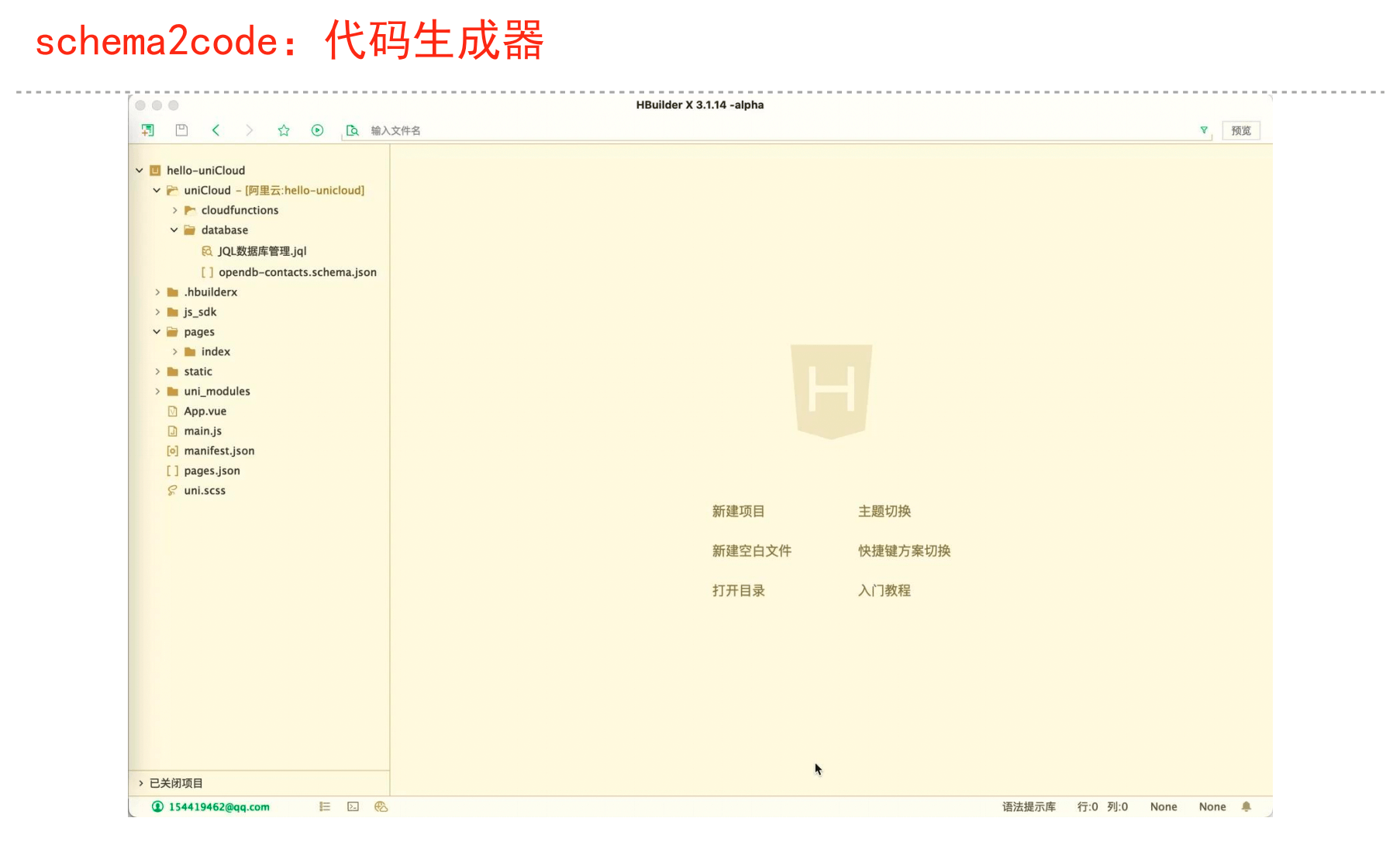
业务抽象schema,一键生成前后端代码
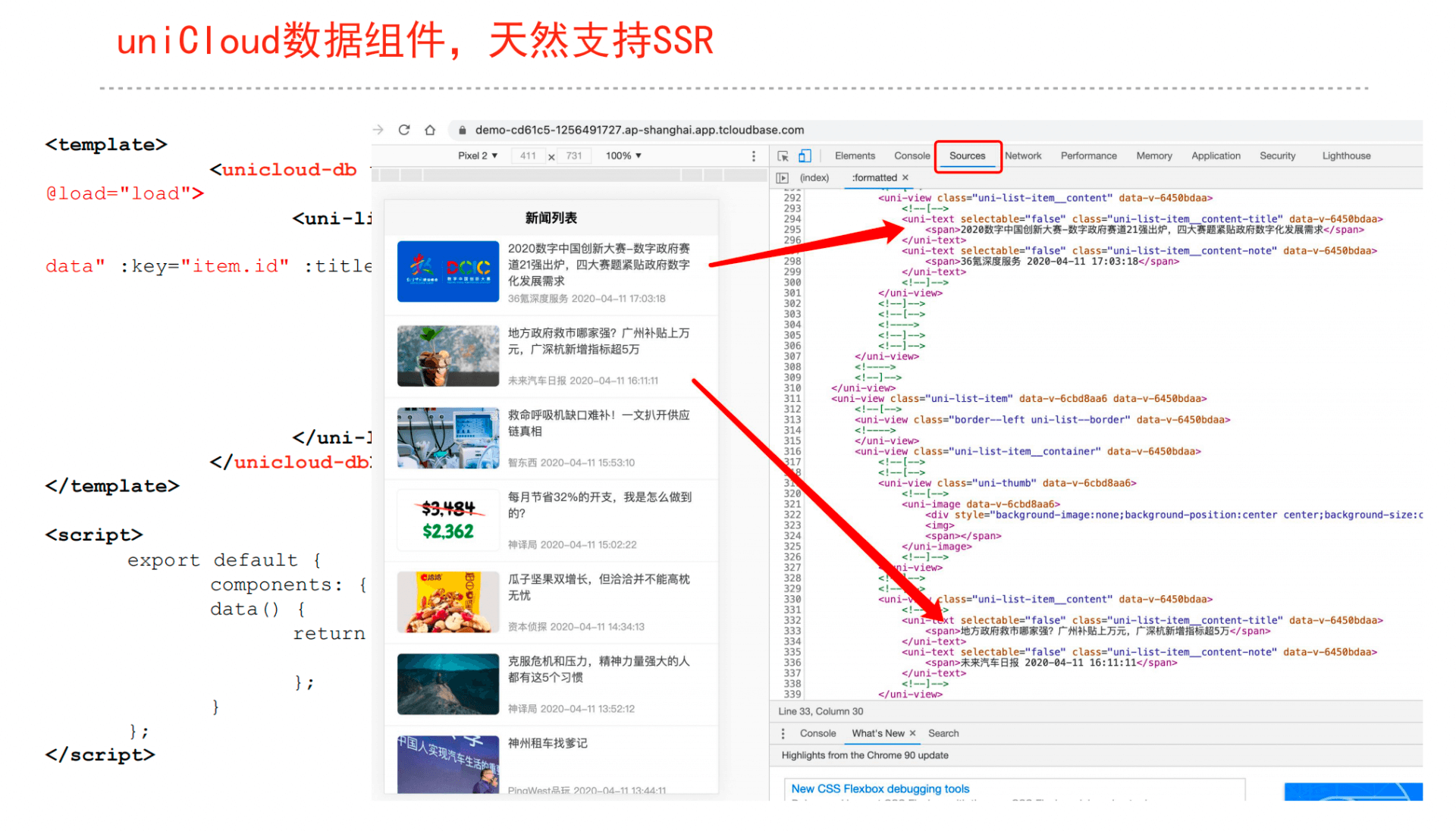
组件支持SSR,降低SSR门槛
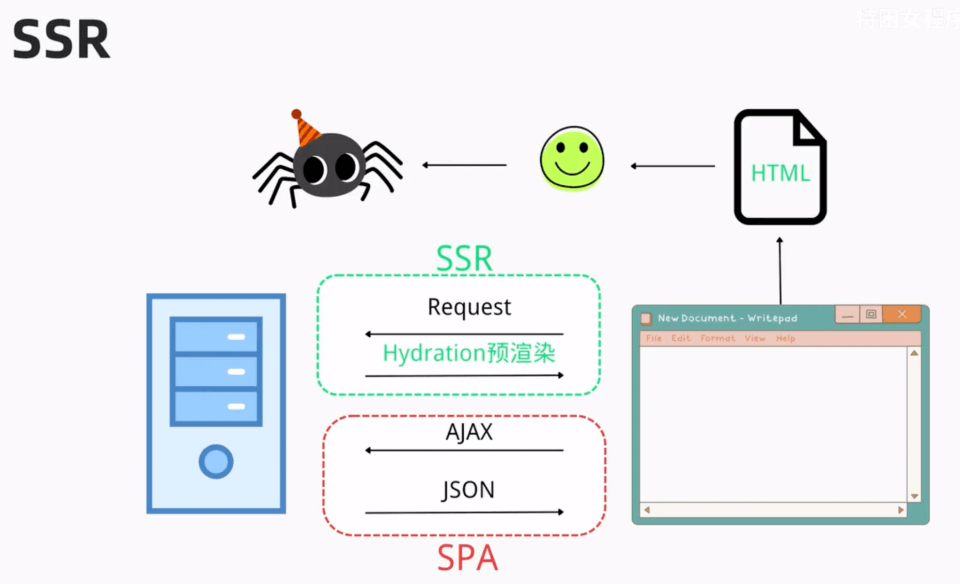
SSR:Server Side Render 是一种将服务端渲染和客户端渲染结合起来的技术,它可以在服务端生成HTML代码,并将其发送到浏览器端。
SPA:Single Page Application 单页面应用,一般也成为客户端渲染 CSR(Client Side Render)
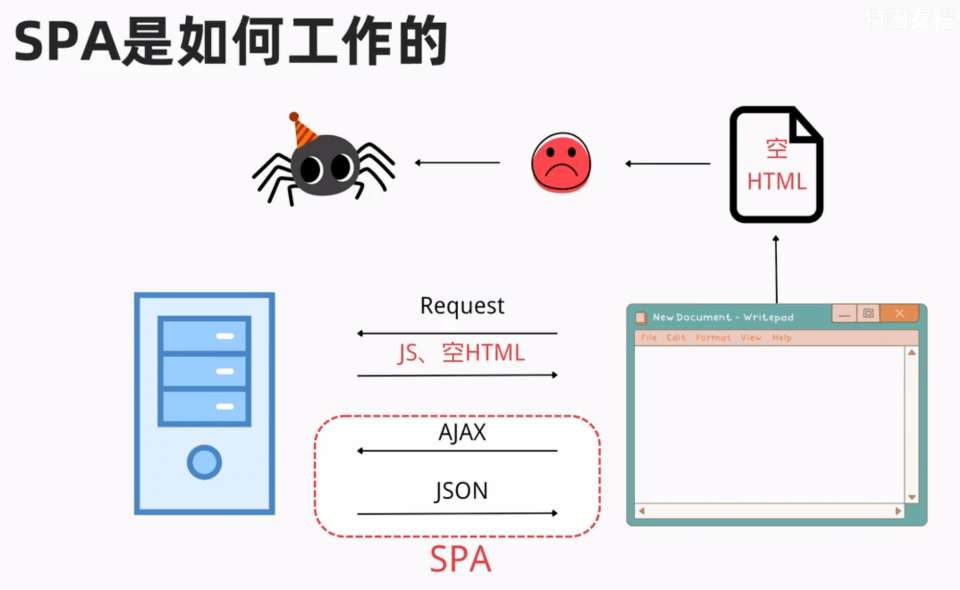
SPA存在的问题:
SSR优点:



云端一体轮子,聚焦业务
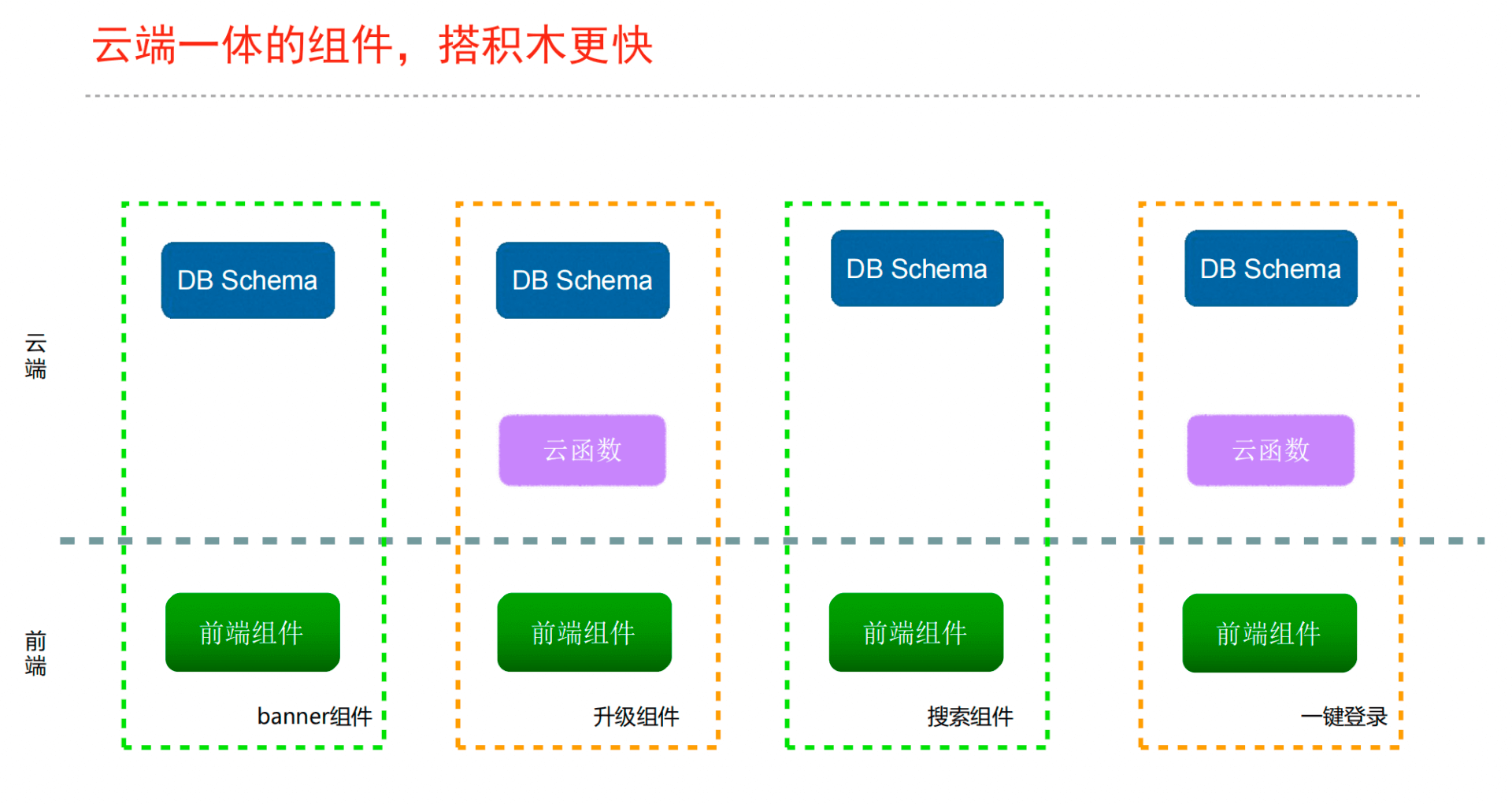
发起请求增加参数
1 | baiduCORS: true, |
原因:web化需要开启直连请求,目前只有线上域名开启了直连,测试环境也需要开启,否则可能会报跨域错误
操作步骤:预览-Web态预览-在浏览器中预览,然后在浏览器中的链接把https改为http
原因:线下环境是http的,网址也需要是http,否则会报mix-content错误
*.smartapps.baidu.com 而非*.smartapps.cn示例:
正确:https://i0wpll.smartapps.baidu.com/sub-others/pages/course-agreement/course-agreement
错误:https://i0wpll.smartapps.cn/sub-others/pages/course-agreement/course-agreement
原因:*.smartapps.cn webmapp/api/v1/check_session 获取登录状态异常,会提示用户未登录
链接里的&_swebfr=1需要去掉或改成&_swebfr=22,控制是否带
示例:
正确:https://i0wpll.smartapps.baidu.com/sub-others/pages/course-agreement/course-agreement
错误:https://i0wpll.smartapps.baidu.com/sub-others/pages/course-agreement/course-agreement?_swebfr=0
原因:_swebfr=1会带“在百度APP内打开”回流按钮,如果改为_swebfr=0,跳转链接会跳不过去,UI也可能异常
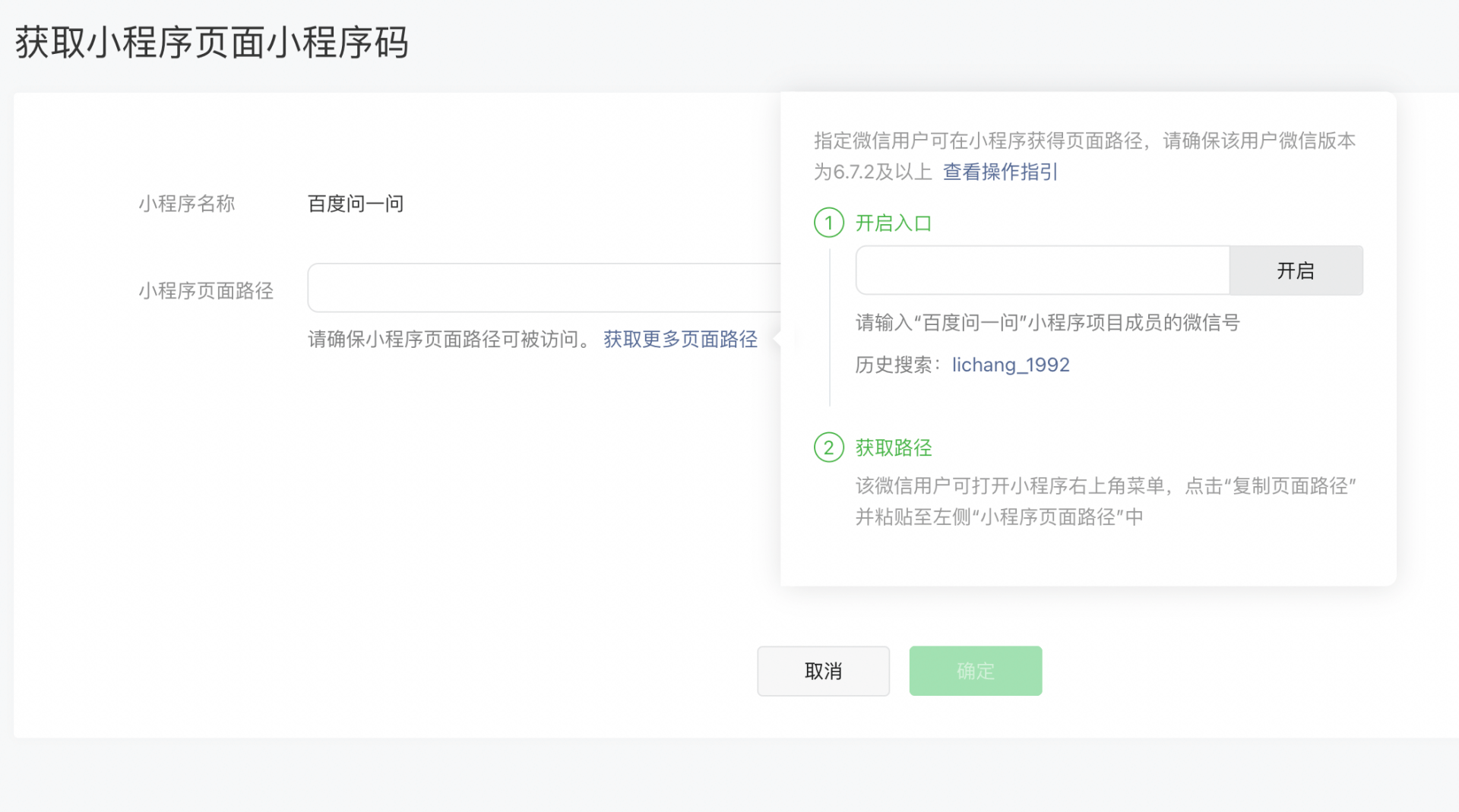
]]>点击右上角三个点-点击“开发调试”,即可访问域名不支持https 带端口号的线下环境
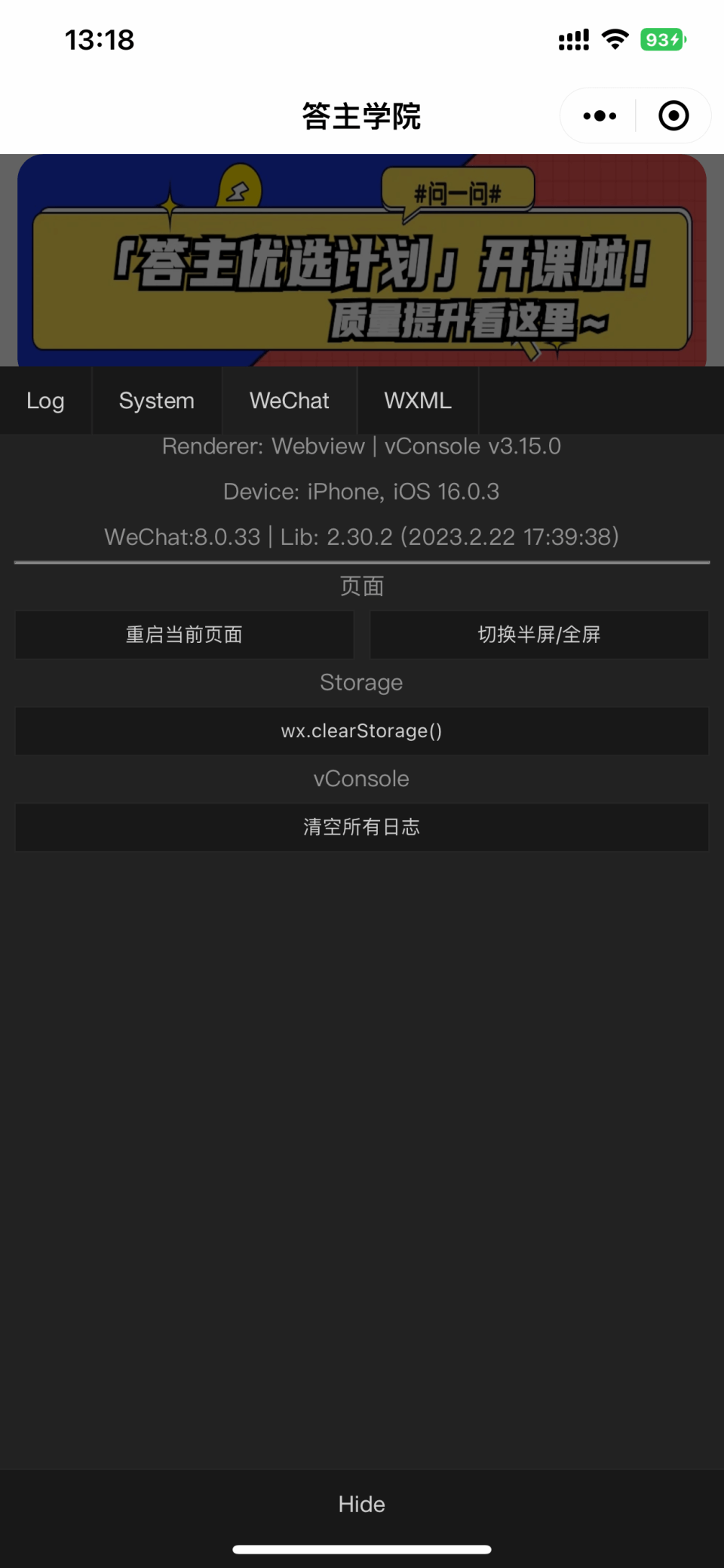
打开“开发调试”后,点击vConsole,可以查看log,清除storage等
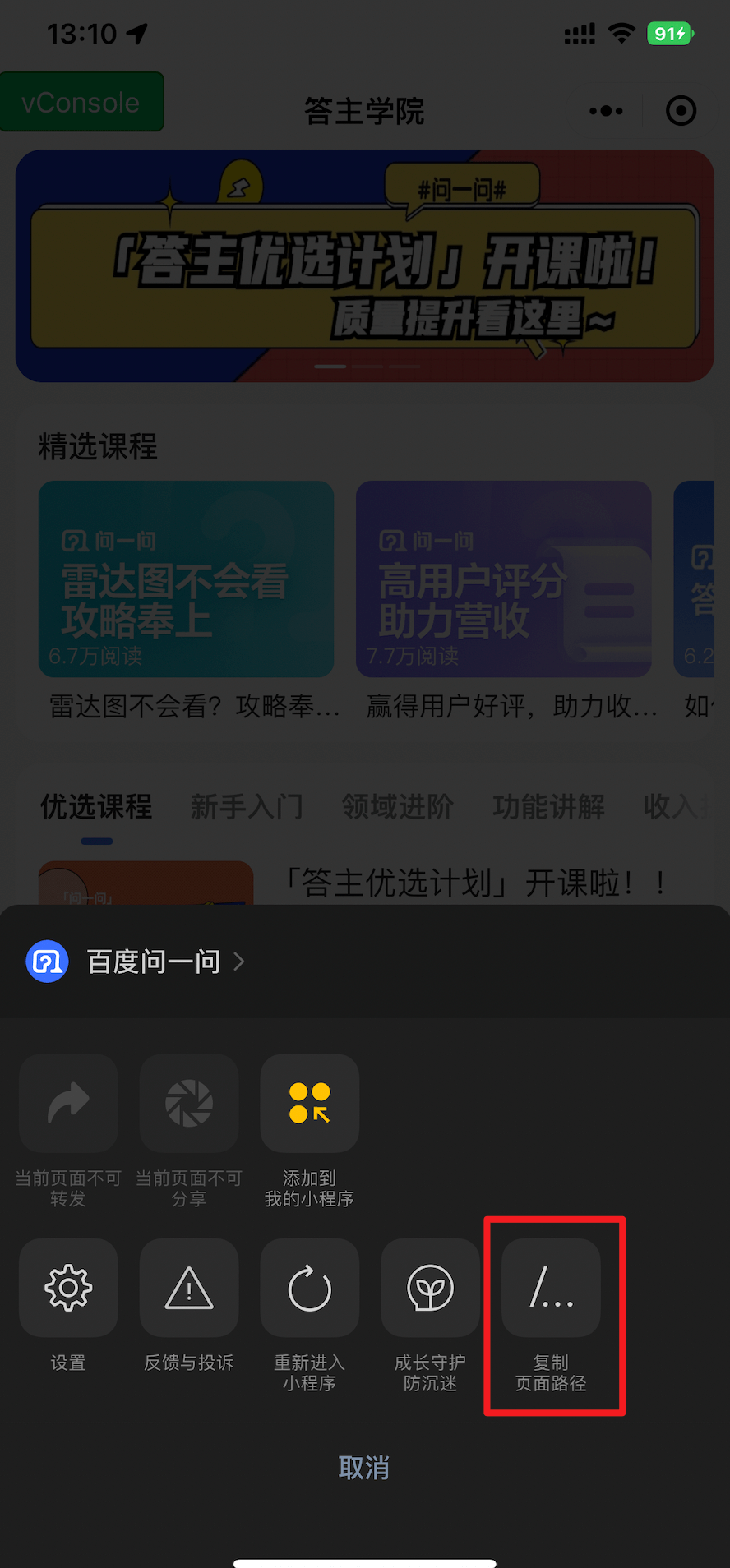
1.父视图需要设置overflow: hidden; 子视图margin-top才生效
2.text标签不生效,需要换成view
参考链接:https://developers.weixin.qq.com/community/develop/article/doc/0008860a8a4370fff76c5147656c13
]]>可以引入Component,相关属性及方法在父组件上。
可以在页面拼参数 eg:hitEid=11245
命中不了实验可能是获取实验的接口 cookie里的baiduid为空
退出登录/重新登录,清缓存,重启IDE
项目信息-本地配置-校验域名 取消勾选
组件进入可视区域展现打点
1 | val: { |
加上.in(this)
1 | // 获取标签rect |
提高权重
1 | /* 提高权重 */ |
需要监听onPageScroll方法,计算上已滑动的距离 currentScrollTop
1 | scrollToRelatedContent(){ |
给属性增加observer,发生改变时调用方法更新其他属性
忽略就行
色值使用小写
建议:color: #3b6fff;
不建议:color: #3B6FFF;
]]>裸眼3D
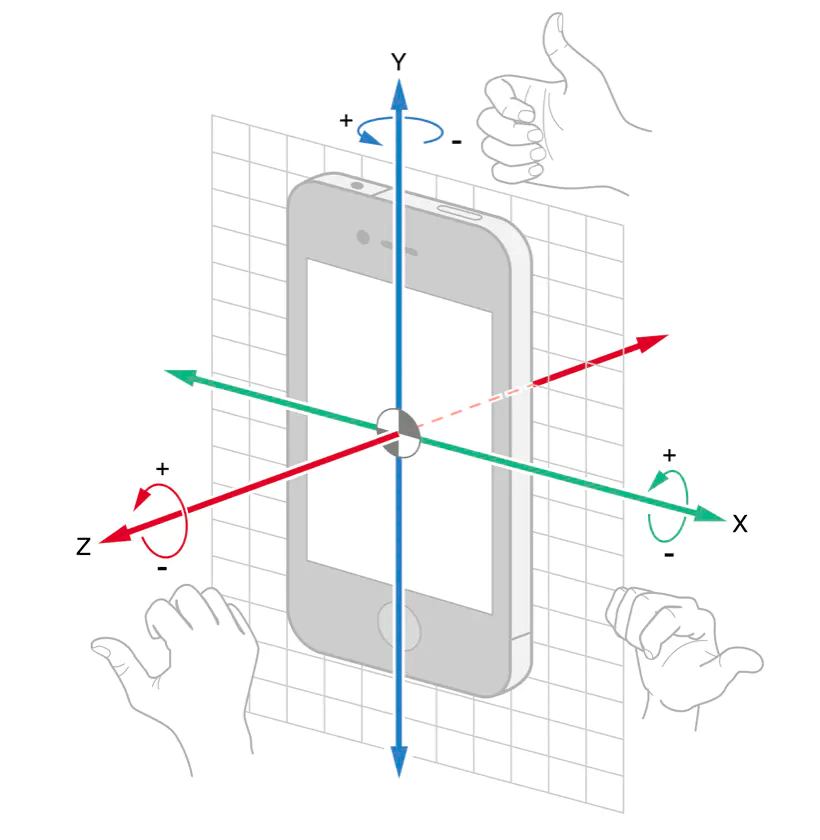
用于启动和管理运动服务的对象。
1 | class CMMotionManager : NSObject |
使用CMMotionManager对象启动报告设备板载传感器检测到的运动的服务。使用此对象接收四种类型的运动数据:
处理后的设备运动数据给出了设备的姿态、旋转速率、校准磁场、重力方向以及用户赋予设备的加速度。
只为您的应用创建一个 CMMotionManager 对象。此类的多个实例会影响从加速度计和陀螺仪接收数据的速率。
您可以按指定的更新间隔接收实时传感器数据,也可以让传感器收集数据并将其存储以供以后检索。使用这两种方法,当您不再需要数据时调用适当的停止方法 (stopAccelerometerUpdates(), stopGyroUpdates(), stopMagnetometerUpdates(),和 stopDeviceMotionUpdates()) 。
为了在特定的时间间隔接收运动数据,app 调用一个“start”方法,该方法采用一个操作队列(OperationQueue的实例)和一个特定类型的block handler 来处理这些更新。运动数据被传递到block handler 中。更新频率由“interval”属性的值决定。
accelerometerUpdateInterval属性以指定更新间隔。调用startAccelerometerUpdates(to:withHandler:) 该方法,传入一个CMAccelerometerHandler类型的block。加速度计数据作为CMAccelerometerData对象传递到block中。gyroUpdateInterval属性以指定更新间隔。调用startGyroUpdates(to:withHandler:) 该方法,传入一个CMGyroHandler类型的块。旋转速率数据作为CMGyroData对象传递到block中。magnetometerUpdateInterval属性以指定更新间隔。调用 startMagnetometerUpdates(to:withHandler:) 该方法,传递一个CMMagnetometerHandler类型的block。磁场数据作为CMMagnetometerData对象传递到block中。deviceMotionUpdateInterval以指定更新间隔。调用startDeviceMotionUpdates(using:) 或startDeviceMotionUpdates(using:to:withHandler:) 或 startDeviceMotionUpdates(to:withHandler:) 方法,传入一个CMDeviceMotionHandler类型的块。旋转速率数据作为CMDeviceMotion对象传递到block中。1 | CMMotionManager *motionManager = [[CMMotionManager alloc] init]; |
为了通过周期性采样来处理运动数据,应用程序调用一个不带参数的“start”方法,并周期性地访问给定类型运动数据的属性所保存的运动数据。这种方法是游戏等应用程序的推荐方法。在一个block中处理加速度计数据会带来额外的开销,并且大多数游戏应用程序只对渲染帧时的最新运动数据样本感兴趣。
startAccelerometerUpdates() 以开始更新并通过读取accelerometerData 属性定期访问CMAccelerometerData 对象。startGyroUpdates() 以开始更新并通过读取gyroData 属性定期访问CMGyroData 对象。startMagnetometerUpdates() 以开始更新并通过读取magnetometerData 属性定期访问CMMagnetometerData对象。startDeviceMotionUpdates(using:)或startDeviceMotionUpdates()方法开始更新并通过读取deviceMotion属性定期访问CMDeviceMotion对象。该方法(iOS 5.0 中的新方法)允许您指定用于姿态估计的参考框架。1 | CMMotionManager *motionManager = [[CMMotionManager alloc] init]; |
CMDeviceMotion1 | CMDeviceMotion : CMLogItem |
如果某个硬件功能(例如陀螺仪)在设备上不可用,则调用与该功能相关的启动方法无效。您可以通过检查相应的属性来了解硬件功能是否可用或处于活动状态;例如,对于陀螺仪数据,您可以检查isGyroAvailable或isGyroActive属性的值。
1 | #import <CoreMotion/CoreMotion.h> |
1 | mSensorManager = (SensorManager) getContext().getSystemService(Context.SENSOR_SERVICE); |
1 | if (event.sensor.getType() == Sensor.TYPE_ACCELEROMETER) { |
1 | if (mDegreeY <= 0 && mDegreeY > mDegreeYMin) { |
Android Studio 下载地址:https://developer.android.google.cn/studio
Flutter SDK 下载地址:https://flutter.dev/docs/get-started/install/macos
添加用户环境变量
打开终端,输入vim ~/.bash_profile,回车,编辑/.bash_profile文件。1
vim ~/.bash_profile
点击i进入编辑模式。
将如下环境变量加入到用户环境变量中:
1 | export PATH=`pwd`/flutter/bin:$PATH |
编辑完成,点击“Esc键,退出insert模式”, 然后输入“:wq”,回车,保存成功。
输入source ~/.bash_profile,让环境变量生效。
输入echo $PATH,查看环境变量,发现添加成功。
输入flutter-h查看是否配置成功。
运行flutter doctor检测环境。
执行flutter doctor后提示 Android license status unknown.
执行 flutter doctor --android-licenses后提示
Android sdkmanager tool not found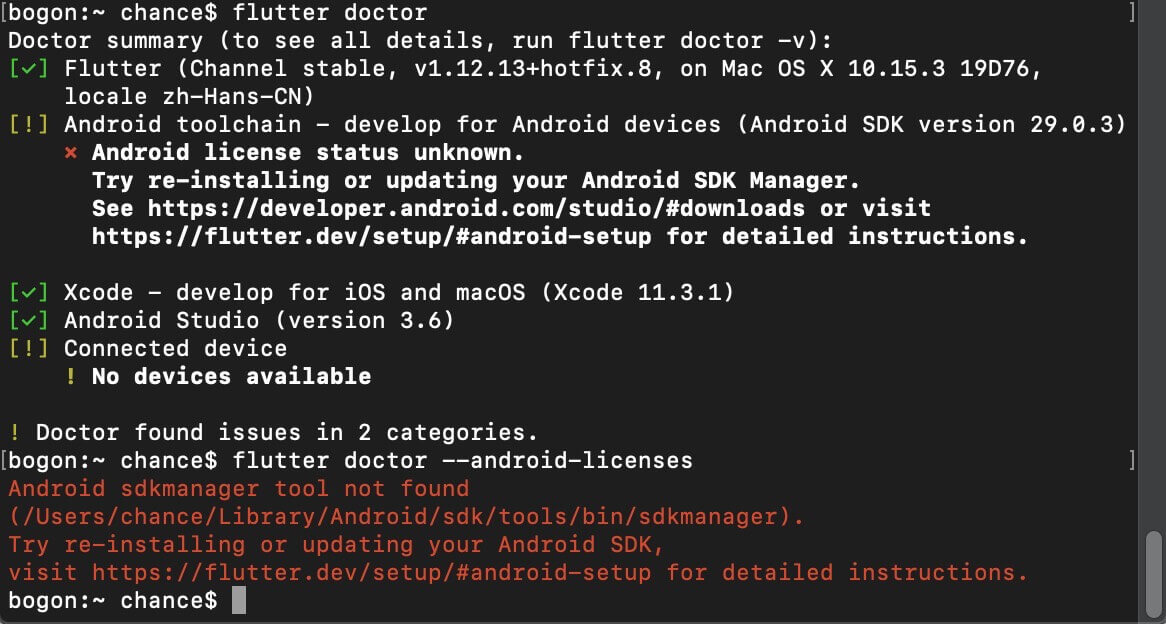
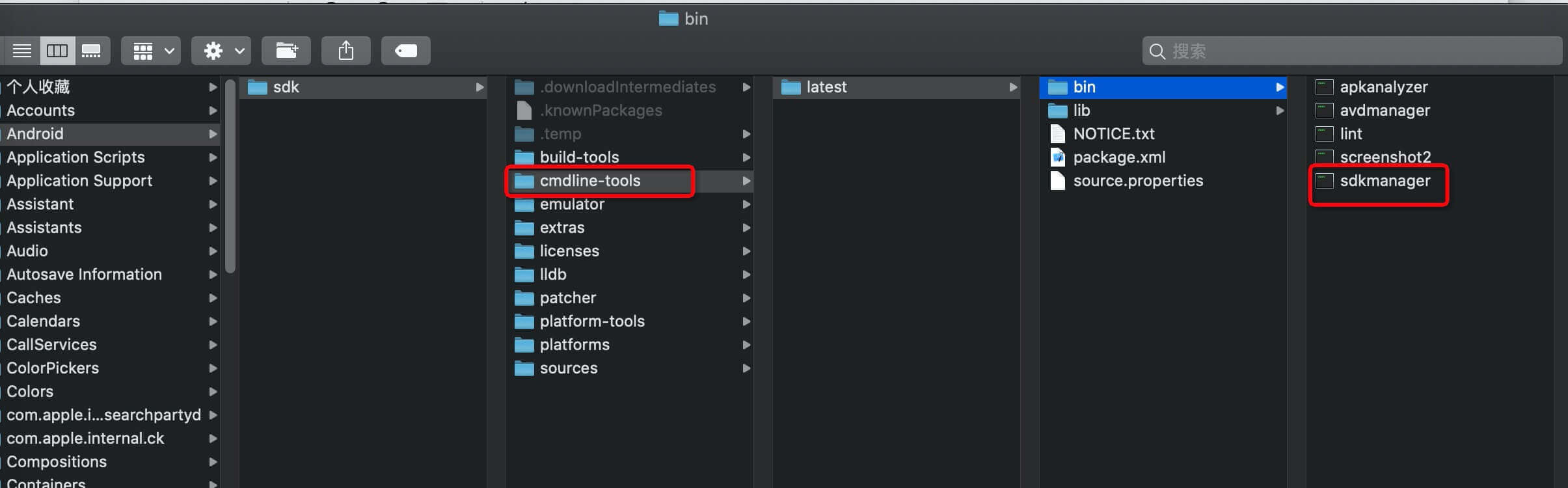
Android Studio 3.6.1版本没有tools文件夹。sdkmanager是在Android/sdk/cmdline-tools/latest/bin/sdkmanager路径下。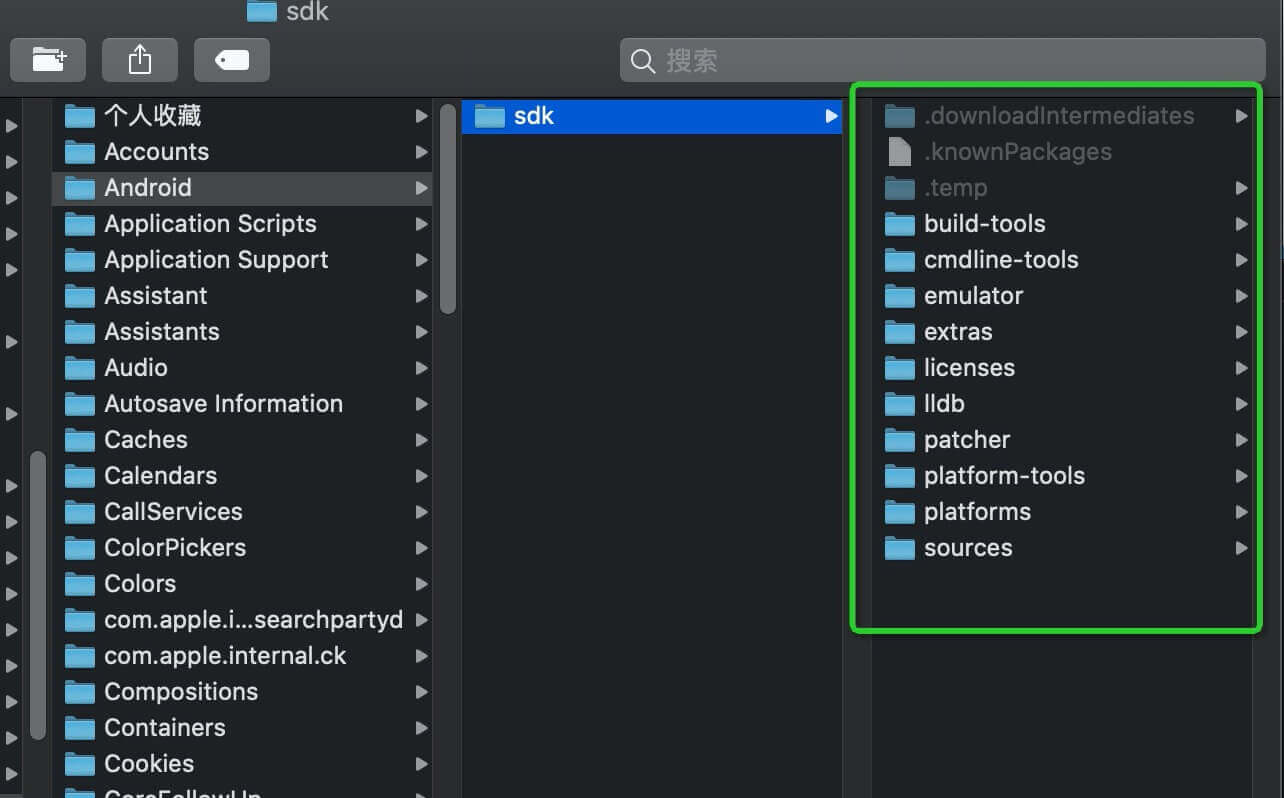
找到偏好设置里Android SDK下的隐藏废弃包取消掉,下载废弃的Android SDK Tools(Obsolete)。
Preferences-Appearance & Behavior-System Settings-Android SDK-SDK Tools
把 Hide Obsolete Packages 前边的对勾取消掉。这时候会显示出隐藏的废弃包Android SDK Tools(Obsolete)。勾选上后,点击Apply下载Android SDK Tools。下载完成后问题得以解决。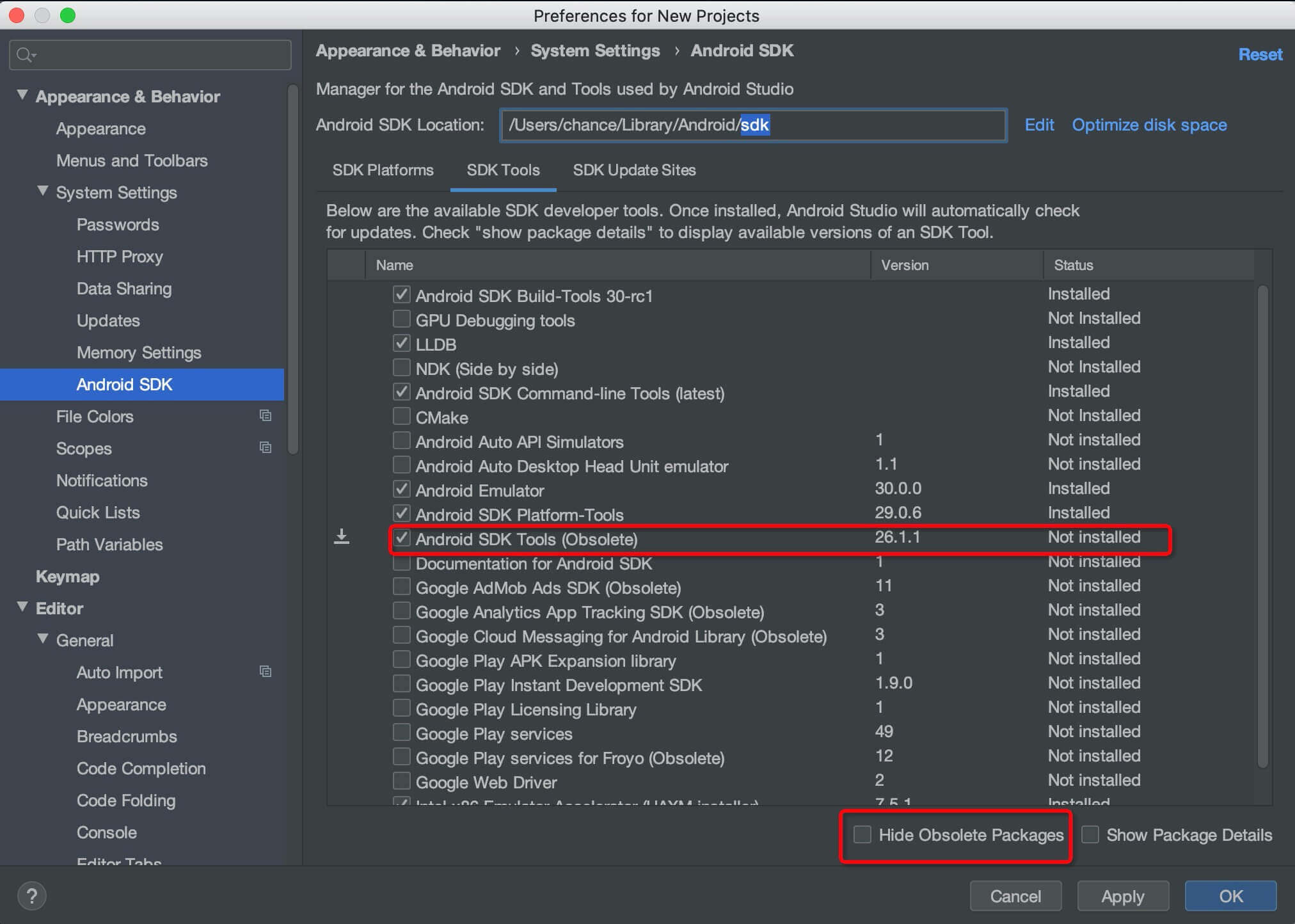
1 | void main() { |
final 可以开始不赋值,只能赋值一次;而final不仅有const的编译时常量的特性,最重要的它是运行时常量,并且final是惰性初始化,即在运行时第一次使用前才初始化。
字符串定义可以用单引号,“” 也可以用‘双引号’,成对出现。
String str1 = ‘this is str1’;
三个单引号(双引号) 可以定义多行字符串
字符串的拼接1
2
3print($str1 $str2);
print(str1 + str2);
int1
2
3
4
5int a = 123
double b = 23.5
print(a);
double既可以是整型 也可以是浮点型
1 | bool flag1 = true; |
1 |
|
1 | var person = { |
is 关键字判断类型
1 | + - * / |
关系运算符 == != > < >= <=
逻辑运算符 ! && ||
赋值运算符 == ??= 从右向左1
2
3
4
5
6int b;
b ??= 23; //如果b为空 把23赋值给b
//+= -= *= /= ~/=
a += 3; a = a+3;
条件表达式 if else switch case1
2
3
4
5if() {
}else {
}
三目运算符 ? :
?? 运算符
数值类型转换成String toString()
String转换成int int.parse()
try catch
其他类型转换布尔类型
isEmpty:判断字符串是否为空
NaN not a number isNaN 是否是数值
自增自减 ++ – 在赋值运算中,如果++在前边,先运算后赋值。如果++在后边,先赋值后运算。
1 | a++; //a=a+1; |
1 | for(int i =1;i<=10;i++) { |
while(){
}
do{
}while()
break 跳出当前循环,只能跳出一层循环
continue 跳过当次循环,循环还会继续执行
属性
方法
add(‘桃子’) 增加元素
addAll() 增加数组里的元素
indexOf(‘苹果’) 查找数据 查找不到返回-1 找到返回index
remove(‘西瓜’)
fillRange 修改
insert 插入
insertAll 插入多个
myList.join(‘’) //list转换成字符串
str.split(‘-‘) 字符串转换成list
Set 集合 去重
常用属性
keys
values
isEmpty
isNotEmpty
常用方法
addAll
remove
containsValue
1 | myList.forEach((value) { |
map
1 | List myList = [1,3,4]; |
where
1 | List myList = [1,3,4,5,7,8,9]; |
any
1 | List myList = [1,3,4,5,7,8,9]; |
every
1 | List myList = [1,3,4,5,7,8,9]; |
返回类型 方法名称(参数1,参数2,…) {
方法体
return 返回值;
}
1 | void printInfo(){ |
1 | //可选参数 |
1 | String printUserInfo(String username,{String sex = '男',int age}) { |
1 | var fn = (){ |
1 | List list = ['苹果','香蕉','西瓜']; |
1 | List list = [4,1,2,3,4]; |
1 | var printNum = (){ |
1 | ((int n){ |
1 | var sum = 1; |
常驻内存,不污染全局
1.全局变量特点:全局变量常驻内存、全局变量污染全局
2.局部变量特点:不常住内存会被垃圾机制回收、不会污染全局
1 | fn() { |
默认构造函数只能定义一个
命名构造函数可以定义多个
1 | class Person{ |
使用_把一个属性或者方法定义成私有。需要把类抽离成一个文件
1 | class Rect { |
1 | class Rect { |
1.使用static关键字来实现类级别的变量和函数
2.静态方法不能访问非静态成员,非静态方法可以访问静态成员
1 | class Person { |
? 条件运算符
as 类型转换
is 类型判断
.. 级联操作(连缀)
1 | class Person { |
1 | var p1; |
1 | Person p1 = new pERSON('张三',20); |
1 | class Web extends Person { |
抽象类:主要用于定义标准,子类可以继承抽象类,也可以实现抽象类接口。
抽象方法 没有方法体的方法
1 | //抽象类 |
允许将子类类型的指针赋值给父类类型的指针,同一个函数调用会有不同的执行结果。
子类的实例赋值给父类的引用。
多态就是父类定义一个方法不去实现,让继承他的子类去实现,每个子类有不同的表现。
1 | Animal d = new Dog(); |
使用抽象类定义接口
1 | abstract class Db { //当做接口 接口:就是约定、规范 |
1.如果要复用抽象类里面的方法,并且要用抽象方法约束子类的话就用extends继承抽象类。
2.如果只是把抽象类当做标准的话就用implements实现抽象类。
1 | abstract class A { |
1 | class A { |
解决类 接口 方法的复用性、以及对不特定数据类型的支持(类型校验)
1 | //泛型方法 |
树(Tree)是 n(n≥0)个结点的有限集。n=0 时称为空树。在任意一棵非空树中:(1)有且仅有一个特定的称为根(Root)的结点;(2)当 n>1 时,其余结点可分为 m(m>0)个互不相交的有限集 T1、T2、……、Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
树(Tree)是 n(n≥0)个结点的有限集。n=0 时称为空树。在任意一棵非空树中:(1)有且仅有一个特定的称为根(Root)的结点;(2)当 n>1 时,其余结点可分为 m(m>0)个互不相交的有限集 T1、T2、……、Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
树的结点包含一个数据元素及若干指向其子树的分支。
结点拥有的子树数称为结点的度(Degree)。度为 0 的结点称为叶结点(Leaf)或终端结点;度不为 0 的结点称为非终端结点或分支结点。除根结点之外,分支结点也称为内部结点。树的度是树内各结点的度的最大值。
结点的子树的根称为该结点的孩子(Child),相应的,该结点称为孩子的双亲(Parent)。同一个双亲的孩子之前互称兄弟(Sibling)。结点的祖先是从根到该结点所经分支上的所有结点。反之,以某结点为根的子树中的任一结点都称为该结点的子孙。
结点的层次(Level)从根开始定义起,根为第一层,根的孩子为第二层。若某结点在第 1 层,则其子树的根就在第 i+1 层。其双亲在同一层的结点互为堂兄弟。树中结点的最大层次称为树的深度(Depth)或高度。
如果将树中结点的各子树看成从左至右是有次序的,不能互换的,则称该树为有序树,否则称为无序树。
森林(Forest)是 m(m≥0)棵互不相交的树的集合。
线性表与树结构
| 线性结构 | 树结构 |
|---|---|
| 第一个数据元素:无前驱 | 根结点:无双亲,唯一 |
| 最后一个数据元素:无后继 | 叶结点:无孩子,可以多个 |
| 中间元素:一个前驱一个后继 | 中间结点:一个双亲多个孩子 |
ADT 树(tree)
Data
树是由一个根结点和若干子树构成。树中结点具有相同数据类型及层次关系。
Operation
InitTree(*T):构造空树 T。
DestroyTree(*T):销毁树 T。
CreateTree(*T, definition):按 definition 中给出树的定义来构造树。
ClearTree(*T):若树 T 存在,则将树 T 清为空树。
TreeEmpty(*T):若 T 为空树,返回 true,否则返回 false。
TreeDepth(T):返回 T 的深度。
Root(T):返回树的根结点。
Value(T, cur_e):cur_e 是树 T 中一个结点,返回此结点的值。
Assign(T, cur_e,value):给树 T 的结点 cur_e 赋值为 value。
Parent(T, cur_e):若 cur_e 是树 T 的非根结点,则返回它的双亲,否则返回空。
LeftChild(T, cur_e):若 cur_e 是树 T 的非叶结点,则返回它的最左孩子,否则返回空。
RightSibling(T, cur_e):若 cur_e 有右兄弟,则返回它的右兄弟,否则返回空。
InsertChild(T, p, i, c):其中 p 指向树 T 的某个结点,i 为所指结点 p 的度加上1,非空树 c 与 T 不相交,操作结果为插入 c 为树 T 中 p 指结点的第 i 棵子树。
DeleteChild(T, p, i):其中 p 指向树 T 的某个结点,i 为所指结点 p 的度,操作结果为删除 T 中 p 所指结点的第 i 棵子树。
endADT
我们假设以一组连续空间存储树的结点,同时在每个结点中,附设一个指示器表示其双亲结点在数组中的位置。也就是说,每个结点除了知道自己是谁以外,还知道它的双亲在哪里。
以下是我们的双亲表示法的结点结构定义代码。
1 | /* 树的双亲表示法结点结构定义 */ |
存储结构的设计是一个非常灵活的过程。一个存储结构设计的是否合理,取决于基于该存储结构的运算是否合适、是否方便,时间复杂度好不好等。
由于树中每个结点可能有多棵子树,可以考虑用多重链表,即每个结点有多个指针域,其中每个指针指向一棵子树的根结点,我们把这种方法叫做多重链表表示法。
孩子表示法。把每个结点的孩子结点排列起来,以单链表作存储结构,则 n 个结点有 n 个孩子链表,如果是叶子结点则此单链表为空。然后 n 个头指针又组成一个线性表,采用顺序存储结构,放进一个一维数组中。
以下是我们的孩子表示法的结构定义代码。
1 | /* 树的孩子表示法结构定义 */ |
任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。因此,我们设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟。
结构定义代码如下。
1 | /* 树的孩子兄弟表示法结构定义 */ |
二叉树(Binary Tree)是 n(n≥0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树的二叉树组成。
二叉树的特点有:
二叉树具有五种基本形态:
所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。这两者统称为斜树。
在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层,这样的二叉树称为满二叉树。
满二叉树的特点有:
(1)叶子只能出现在最下一层。
(2)非叶子结点的度一定是 2。
(3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子树最多。
对一棵具有 n 个结点的二叉树按层序编号,如果编号为 i(1≤i≤n)的结点与同样深度的满二叉树中编号为 i 的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。
完全二叉树的特点:
(1)叶子结点只能出现在最下两层。
(2)最下层的叶子一定集中在左部连续位置。
(3)倒数二层,若有叶子结点,一定都在右部连续位置。
(4)如果结点度为1,则该结点只有左孩子,即不存在只有右子树的情况。
(5)同样结点的二叉树,完全二叉树的深度最小。
判断某个二叉树是否是完全二叉树的办法,就是看着树的示意图,心中默默给每个结点按照满二叉树的结构逐层顺序编号,如果编号出现空挡,就说明不是完全二叉树,否则就是。
性质1:在二叉树的第 i 层上至多有 2i-1 个结点(i≥1)。
性质2:深度为 k 的二叉树至多有 2k-1 个结点(k≥1)。
性质3:对任何一棵二叉树 T,如果其终端结点数为 n0,度为 2 的结点数为 n2,则 n0=n2+1。
性质4:具有 n 个结点的完全二叉树的深度为 ⎣log2n⎦+1 ( ⎣x⎦表示不大于 x 的最大整数)。
注:⎣⎦ 向下取整运算。
性质5:如果对于一棵有 n 个结点的完全二叉树(其深度为 ⎣log2n⎦+1)的结点按层序编号(从第 1 层到第 ⎣log2n⎦+1 层),每层从左到右,对任一结点 i (1≤i≤n)有:
顺序存储结构一般只用于完全二叉树。
二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域是比较自然的想法,我们称这样的链表叫做二叉链表。
以下是我们的二叉链表的结点结构定义代码。
1 | /* 二叉树的二叉链表结点结构定义 */ |
二叉树的遍历(traversing biary tree)是指从根结点出发,按照某种次序依次访问二叉树中所有结点,使得每个结点被访问一次且仅被访问一次。
规则是若二叉树为空,则空操作返回,否则先访问根结点,然后前序遍历左子树,再前序遍历右子树。
规则是若树为空,则空操作返回,否则从根结点开始(注意不是先访问根结点),中序遍历根结点的左子树,然后是访问根结点,最后中序遍历右子树。
规则是若树为空,则空操作返回,否则从左到右先叶子后结点的方式遍历访问左右子树,最后是访问根结点。
规则是若树为空,则空操作返回,否则从树的第一层,也就是根结点开始访问,从上而下逐层遍历,在同一层中,按从左到右的顺序对结点逐个访问。
1 | /* 二叉树的前序遍历递归算法 */ |
1 | /* 二叉树的中序遍历递归算法 */ |
1 | /* 二叉树的后序遍历递归算法 */ |
1 | /* 按前序输入二叉树中结点的值(一个字符) */ |
指向前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,相应的二叉树就称为线索二叉树(Threaded Binary Tree)。
对二叉树以某种次序遍历使其变为线索二叉树的过程叫做是线索化。
1 | /* 二叉树的二叉线索存储结构定义 */ |
线索化的过程就是在遍历的过程中修改空指针的过程。
如果所用的二叉树需经常遍历或查找结点时需要某种遍历序列中的前驱和后继,那么采用线索二叉链表的存储结构就是非常不错的选择。
将树转换为二叉树的步骤如下
步骤如下:
树的遍历分为两种方式。
森林的遍历也分为两种方式:
从树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称做路径长度。
树的路径长度就是从树根到每一个结点的路径长度之和。
带权路径长度 WPL 最小的二叉树称做赫夫曼树。
一般地,设需要编码的字符集为{d1,d2,…,dn},各个字符在电文中出现的次数或频率集合为 {w1,w2,…,wn},以 d1,d2,…,dn 作为叶子结点,以 w1,w2,…,wn 作为相应叶子结点的权值来构造一棵赫夫曼树。规定赫夫曼树的左分支代表 0,右分支代表 1,则从根结点到叶子结点所经过的路径分支组成的 0 和 1 的序列便为该结点对应字符的编码,这就是赫夫曼编码。
]]>串(string)是由零个或多个字符组成的有限序列,又名叫字符串。
串(string)是由零个或多个字符组成的有限序列,又名叫字符串。
给定两个串:s= “a1a2……an“, t= “b1b2……bm“, 当满足以下条件之一时,s<t。
1 | ADT 串(string) |
Index 的实现算法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/* T为非空串。若主串S中第pos个字符之后存在与T相等的子串,则返回第一个这样的子串在S中的位置,否则返回0 */
int Index(String S, String T, int pos)
{
int n,m,i;
String sub;
if (pos > 0)
{
n = StrLength(S);
m = StrLength(T);
i = pos;
while ( i <= n-m+1)
{
SubString(sub,S,i,m); /* 取主串第i个位置 长度与T相等子串给sub */
if (StrCompare(sub,T) != 0) /* 如果两串不相等 */
++i;
else /* 如果两串相等 */
return i;
}
}
return 0; /* 若无子串与T相等,返回0 */
}
当中用到了 StrLength、SubString、StrCompare 等基本操作来实现。
串的顺序存储结构是用一组地址连续的存储单元来存储串中的字符序列的。按照预定义的大小,为每个定义的串变量分配一个固定长度的存储区。一般使用定长数组来定义。
对于串的链式存储结构,与线性表是相似的,但由于串结构的特殊性,结构中的每个元素数据是一个字符,如果也简单的应用链表存储串值,一个结点对应一个字符,就会存在很大的空间浪费。因此,一个结点可以存放一个字符,也可以考虑存放多个字符,最后一个结点若是未被占满时,可以用“#”或其他非串值字符补全。
串的链式存储结构除了在链接串与串操作时有一定方便外,总的来说不如顺序存储灵活,性能也不如顺序存储结构好。
子串的定位操作通常称做串的模式匹配。
假设我们要从下面的主串S=“goodgoogle”中,找到T=“google这个子串的位置”。
简单的来说,就是对主串的每一个字符作为子串开头,与要匹配的字符串进行匹配。对主串做大循环,每个字符开头做T的长度的小循环,直到匹配成功或全部遍历完成为止。
最好的情况,时间复杂度为O(1)。
稍差一些的情况,时间复杂度为O(n+m),其中n为主串长度,m为要匹配的子串长度。
根据等概率原则,平均是(n+m)/2次查找,时间复杂度为O(n+m)。
D.E.Knuth、J.H.Morris 和 V.R.Pratt 发表一个模式匹配算法,可以大大避免重复遍历的情况,我们把它称之为克努特-莫里斯-普拉特算法,简称 KMP 算法。
]]>优化前:37.8MB 优化后:15.7MB
优化前:27.7MB 优化后:9.2MB
通过这次实践,我发现影响包大小的主要因素是某些较大的第三方库及库里的图片,以及支持iPhone 4、4s 的 armv7。对于用不到的类、图片等资源文件要及时清理,使用被蓝湖等工具压缩过的图片等方式来改善安装包大小。
]]>栈是限定仅在表尾进行插入和删除操作的线性表。
队列是只允许在一端进行插入操作、而在另一端进行删除操作的线性表。
栈(stack)是限定仅在表尾进行插入和删除操作的线性表。
我们把允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom),不含任何数据元素的栈称为空栈。栈又称为后进先出(Last In First Out)的线性表,简称 LIFO 结构。
栈的插入操作,叫做进栈,也称压栈、入栈。
栈的删除操作,叫做出栈,也有的叫弹栈。
元素数量多个,出栈次序会有很多种可能。
1 | ADT 栈 |
栈的结构定义1
2
3
4
5
6typedef init SElemType;
typedef struct
{
SElemType data[MAXSIZE]
int top; /* 用于栈顶指针 */
}SqStack;
进栈操作 push,其代码如下:1
2
3
4
5
6
7
8
9
10Status Push (SqStack *S, SElemType e)
{
if (S->top == MAXSIZE - 1) /* 栈满 */
{
return ERROR;
}
S->top++; /* 栈顶指针增加一 */
S->data[S->top]=e; /* 将新插入元素赋值给栈顶空间 */
return OK;
}
出栈操作 pop,其代码如下:1
2
3
4
5
6
7
8Status Pop (SqStack *S, SElemType *e)
{
if(S->top==-1)
return ERROR;
*e=S->data[S->top]; /* 将要删除的栈顶元素赋值给e */
S->top--; /* 栈顶指针减一 */
return OK;
}
进栈和出栈没有涉及到任何循环语句,因此时间复杂度均是 O(1)。
使用这样的数据结构,通常都是当两个栈的空间需求有相反关系时,也就是一个栈增长时另一个栈在缩短的情况。
栈的链式存储结构,简称为链栈。
链栈的结构代码如下:1
2
3
4
5
6
7
8
9
10
11typedef struct StackNode
{
SElemType data;
struct StackNode *next;
}StackNode, *LinkStackPtr;
typedef struct LinkStack
{
LinkStackPtr top;
int count;
}
1 | /* 插入元素 e 为新的栈顶元素 */ |
假设变量 p 用来存储要删除的栈顶结点,将栈顶指针下移一位,最后释放 p 即可。1
2
3
4
5
6
7
8
9
10
11
12Status Pop (LinkStack *S, SElemType *e)
{
LinkStackPtr p;
if (StackEmpty(*S))
return ERROR;
*e = S->top->data;
p=S->top; /* 将栈顶结点赋值给p */
S->top=S->top->next; /* 使得栈顶指针下移一位,指向后一结点 */
free(p); /* 释放结点 p */
S->count--;
return OK;
}
链栈的进栈 push 和出栈 pop 操作没有任何循环操作,时间复杂度均为O(1)。
如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
栈的引入简化了程序设计的问题,划分了不同关注层次,使得思考范围缩小,更加聚焦于我们要解决的问题核心。
1 | int Fbi (int i) |
在高级语言中,调用自己和其他函数并没有本质的不同。我们把一个直接调用自己或通过一系列的调用语句间接地调用自己的函数,称做递归函数。
每个递归定义必须至少有一个条件,满足递归不再进行,即不再引用自身而是返回值退出。
将中缀表达式转化为后缀表达式(栈用来进出运算的符号)。
将后缀表达式进行运算得出结果(栈用来进出运算的数字)。
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头。
1 | ADT 队列(Queue) |
我们把队列的这种头尾相接的顺序存储结构称为循环队列。
队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出而已,我们把它简称为链队列。
链队列的结构为:1
2
3
4
5
6
7
8
9
10
11
12typedef int QElemType;
typedef struct QNode /* 节点结构 */
{
QElemType data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct /* 队列的链表结构 */
{
QueuePtr front,rear; /* 队头、队尾指针 */
}LinkQueue;
1 | Status EnQueue(LinkQueue *Q, QElemType e) |
1 | Status DeQueue(LinkQueue *Q, QElemType *e) |
在可以确定队列长度最大值的情况下,建议用循环队列,如果你无法预估队列的长度时,则用链队列。
]]>在聊天页面,点击输入框弹起键盘,点击IQKeyboardManager带的完成按钮或者点击空白页面收起键盘,反复操作多次后,会出现页面向上偏移,环信UI的工具栏移动到了页面最上边。
在聊天页面禁用IQKeyboardManager。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15- (void)viewDidAppear:(BOOL)animated
{
[super viewDidAppear:animated];
IQKeyboardManager *keyboardManager = [IQKeyboardManager sharedManager];
keyboardManager.enable = NO;
keyboardManager.enableAutoToolbar = NO;
}
- (void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
IQKeyboardManager *keyboardManager = [IQKeyboardManager sharedManager];
keyboardManager.enable = YES;
keyboardManager.enableAutoToolbar = YES;
}
环信服务器不存储用户的昵称头像等用户数据。需要客户端自己来存储并展示在界面上。有几个时机是需要插入或更新一条包含昵称、头像的用户数据到数据库里,比如查看用户详情,在某个页面收到环信消息。我们服务器提供的查询用户信息接口返回的昵称和头像,之前是没有问题的,有一次出现了从用户信息界面进入聊天页面不显示昵称的问题。
经排查,接口返回的用户头像字段的值是null,由于客户端之前没有做空处理,导致插入或更新一条数据失败。1
2DB Query: INSERT or REPLACE INTO t_huanxin (hxId,nickname,avatar) VALUES (?,?,?)
Unknown error finalizing or resetting statement (19: NOT NULL constraint failed: t_huanxin.avatar)
存储用户信息到本地数据库时增加安全判断。如果为空,就存入空字符串。避免插入或更新字段为null导致操作失败。1
2NSString *nickname = dic[@"nickname"]?:@"";
NSString *avatar = dic[@"avatar"]?:@"";
使用环信Demo发送消息,首条消息发送后,下拉刷新,单聊页面会有两条重复的消息。
操作步骤:1.点击单聊页面右上角的清空按钮,清空某个用户的消息。2.返回会话列表。3.首次进入该用户的单聊页面。4.发送首条消息。5.页面下拉刷新。6.出现了两条一摸一样的消息。
在EMChatViewController的tableViewDidTriggerHeaderRefresh方法中增加如下判断。1
2
3
4
5
6
7
8
9
10- (void)tableViewDidTriggerHeaderRefresh
{
//解决首条消息发送后下拉刷新出现两条重复消息的BUG 开始
if (self.dataArray.count && self.moreMsgId == nil) {
[self tableViewDidFinishTriggerHeader:YES reload:NO];
return;
}
//解决首条消息发送后下拉刷新出现两条重复消息的BUG 结束
other code
}
iOS环信Demo聊天页面,发送语音,点击“按住录音”,发送了0秒的聊天记录。
在EMChatViewController的chatBarRecordAudioViewStopRecord:timeLength:方法中增加对录音时长的判断。1
2
3
4
5
6
7
8
9
10
11
12- (void)chatBarRecordAudioViewStopRecord:(NSString *)aPath
timeLength:(NSInteger)aTimeLength
{
EMVoiceMessageBody *body = [[EMVoiceMessageBody alloc] initWithLocalPath:aPath displayName:@"audio"];
body.duration = (int)aTimeLength;
if (body.duration == 0) {
NSLog(@"录音时长为0");
NSLog(@"录制时间过短,不能发送");
return;
}
[self _sendMessageWithBody:body ext:nil isUpload:YES];
}
Done聊天页面,点击查看图片,图片右上角的按钮显示Done,而不是”完成“。
直接全局搜索Done,把环信UI里的Done,替换成”完成“即可。
不想使用环信默认的推送内容:”您有一条新消息”,或”xxx:消息内容”。想实现自定义的消息内容。
发送消息扩展里添加字段em_apns_ext1
2
3
4
5{
nickname:"王小二",
avatar:"http://www.baidu.com",
em_apns_ext:{"em_push_content":"自定义推送内容"}
}
参考链接:环信 APNs 内容解析文档
项目里点击推送通知到落地页采用了路由模式,有一个场景是需要我们自己服务器发推送点击通知栏跳转到聊天页面。路由短链类似:page://chat?from=hxId_10086,由于某些原因,需要带上昵称和头像,加上头像链接后,短链变成了page://chat?from=hxId_10086&avatar=http://www.baidu.com&nickname=王小二,iOS 解析短链的方法是先把短链字符串转成了URL,加了avatar参数之后,转换失败,导致无法跳转。
URL,其实违反了路由链接设计的初衷,可以把avatar的值用AES加密一下传输,避免出现链接。URL,直接处理短链,去解析。iOS无法播放小程序发过来的语音消息iOS无法播放。
Android和iOS发的语音格式都是AMR,小程序发的语音格式是MP3,iOS收到音频后,会先调用_convertAudioFile:方法转换格式,该方法内部实现实现里有一行代码是判断路径是否是MP3文件的,1
[EMAudioPlayerHelper isMP3File:retPath]
这个判断方法有问题,发过来的是MP3,却判断不是MP3,接着音频被当成AMR去转换WAV ,转换音频格式失败,播放失败。
在EMAudioPlayerHelper类中的startPlayerWithPath:model:completion:方法中增加判断,如果含有.mp3,就不转换,直接去播放。不含.mp3,就照旧走_convertAudioFile:转换格式方法。1
2
3
4
5
6if ([aPath containsString:@".mp3"]) {
//不转换
}else {
aPath = [self _convertAudioFile:aPath];
}
// aPath = [self _convertAudioFile:aPath];
iOS发的语音消息,Web/小程序收到后无法播放?App端发来的文件是AMR格式的,小程序需要下载的时候转成MP3格式去播放。转换方法如下:
参考链接:环信 Web IM 音频消息文档
线性表:零个或多个数据元素的有限序列。
线性表(List):零个或多个数据元素的有限序列。
线性表元素的个数 n (n>=0) 定义为线性表的长度,当 n = 0时,称为空表。
ADT 线性表(List)
Data
线性表的数据对象集合为{a1,a2,……,an},每个元素的类型均为DataType。其中,除第一个元素a1外,每一个元素有且只有一个直接前驱元素,除了最后一个元素an外,每一个元素有且只有一个直接后继元素。数据元素之间的关系是一对一的关系。
Operation
InitList (*L):初始化操作,建立一个空的线性表L。
ListEmpty(L):若线性表为空,返回true,否则返回false。
ClearList(*L):将线性表清空。
GetElem(L,i,*e):在线性表L中的第i个位置元素值返回给e。
LocateElem(L,e):在线性表L中查找与给定值e相等的元素,如果查找成功,返回该元素在表中的序号表示成功;否则,返回0表示失败。
ListInsert(*L,i,e):在线性表L中的第i个位置插入新元素e。
ListDelete(L,i, e):删除线性表L中的第i个位置元素,并用e返回其值。
ListLength(L):返回线性表L的元素个数。
endADT
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。
一维数组来实现顺序存储结构。
数组的长度是存放线性表的存储空间的长度。线性表的长度是线性表中数据元素的个数。在任意时刻,线性表的长度应该小于等于数组的长度。
存储器中每个存储单元都有自己的编号,这个编号称为地址。
LOC(ai) = LOC(a1) + (i-1)*c
存取的时间性能为O(1)。
只要i的数值在数组的下标范围内,就是把数组的第i-1下标的值返回即可。
插入算法的思路:
删除算法的思路:
插入和删除的时间复杂度,最好情况为O(1),最坏情况为O(n),平均时间复杂度为O(n)。
优点:
缺点:
为了表示每个数据元素ai与其直接后继数据元素ai+1之间的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称作指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。
n个结点(ai的存储映像)链结成一个链表,即为线性表(a1,a2,…,an)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。
链表中的第一个结点的存储位置叫做头指针。在单链表的第一个结点前附设一个结点,称为头结点。头结点的指针域存储指向第一个结点的指针。
单链表中,我们在C语言中可用结构指针来描述。
1 | /*线性表的单链表存储结构*/ |
获取链表第i个数据的算法思路:
单链表第i个数据插入结点的算法思路:
单链表第i个数据删除结点的算法思路:
头插法
尾插法
单链表整表删除的算法思路如下:
存储分配方式
时间性能
空间性能
用数组描述的链表叫做静态链表,这种描述方法还有起名叫做游标实现法。
静态链表优缺点
优点:在插入和删除操作时,只需要修改游标,不需要移动元素,从而改进了顺序存储结构中的插入和删除操作需要移动大量元素的缺点。
缺点:
将单链表中终端节点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circular linked list)。
双向链表(double linked list)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。
]]>数据类型:是指一组性质相同的值得集合及定义在此集合上的一些操作的总称。
C语言中,按照取值的不同,可以分为两类:
抽象数据类型(Abstract Data Type, ADT):是指一个数学模型及定义在该模型上的一组操作。
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有序序列,并且每条指令表示一个或多个操作。
函数的渐近增长:给定两个函数 f(n) 和 g(n), 如果存在一个整数N,使得对于所有的 n > N, f(n) 总是比 g(n) 大,那么,我们说 f(n) 的增长渐近快于 g(n)。
在进行算法分析时,语句总的执行次数 T(n) 是关于问题规模 n 的函数,进而分析 T(n) 随 n 的变化情况并确定 T(n) 的数量级。算法的时间复杂度,也就是算法的时间度量,记作:T(n) = O(f(n))。它表示随问题规模 n 的增大,算法执行时间的增长率和 f(n) 的增长率相同,称作算法的渐近时间复杂度,简称为时间复杂度。其中 f(n) 是问题规模 n 的某个函数。
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
]]>1 | - (void)getGooodsList |
++ncontainerWidth = 0.3 * Screen_Width2 << (1 + 2 * 3 - 4)当有条件过多、过长的时候需要换行,为了代码看起来整齐些。
1 | //good |
在一个代码块里面有个可能的情况时善于使用 return 来结束异常的情况。
1 | - (void)doHomework |
每个分支的实现都必须使用 {} 包含。
1 | // bad |
条件判断的时候应该是变量在左,条件在右。 if ( currentCursor == 2 ) { //… }
1 | switch (menuType) { |
有时候我们需要为我们创建的类设置一些注释。我们可以在类的下面添加。
枚举的命名和类的命名相近。1
2
3
4
5
6typedef NS_ENUM(NSInteger, UIControlContentVerticalAlignment) {
UIControlContentVerticalAlignmentCenter = 0,
UIControlContentVerticalAlignmentTop = 1,
UIControlContentVerticalAlignmentBottom = 2,
UIControlContentVerticalAlignmentFill = 3,
};
1 | #define HOME_PAGE_DID_SCROLL @"com.xq.home.page.tableview.did.scroll" |
书写规则,基本上就是 @property 之后空一格,括号,里面的 线程修饰词、内存修饰词、读写修饰词,空一格 类 对象名称 根据不同的场景选择合适的修饰符。1
2
3
4@property (nonatomic, strong) UITableView *tableView;
@property (nonatomic, assign, readonly) BOOL loading;
@property (nonatomic, weak) id<#delegate#> delegate;
@property (nonatomic, copy) <#returnType#> (^<#Block#>)(<#parType#>);
单例适合全局管理状态或者事件的场景。一旦创建,对象的指针保存在静态区,单例对象在堆内存中分配的内存空间只有程序销毁的时候才会释放。基于这种特点,那么我们类似 UIApplication 对象,需要全局访问唯一一个对象的情况才适合单例,或者访问频次较高的情况。我们的功能模块的生命周期肯定小于 App 的生命周期,如果多个单例对象的话,势必 App 的开销会很大,糟糕的情况系统会杀死 App。如果觉得非要用单例比较好,那么注意需要在合适的场合 tearDown 掉。
单例的使用场景概括如下:
推荐以_开头,写在 .m 文件中。例如NSString * _somePrivateVariable
1 | - (void)tableView:(UITableView *)tableView willDisplayCell:(UITableViewCell *)cell forRowAtIndexPath:(NSIndexPath *)indexPath; |
方法如果有多个参数的情况下需要注意是否需要介词和连词。很多时候在不知道如何抉择测时候思考下苹果的一些 API 的方法命名。
1 | //good |
.m 文件中的私有方法需要在顶部进行声明
文件基本上就是1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129#import "ViewController.h"
/*ViewController*/
/*View&&Util*/
/*model*/
/*NetWork InterFace*/
/*Vender*/
@interface ViewController ()
@end
@implementation ViewController
#pragma mark - life cycle
- (void)viewWillAppear:(BOOL)animated
{
[super viewDidAppear:animated];
}
- (void)viewDidAppear:(BOOL)animated
{
[super viewDidAppear:animated];
}
- (void)viewDidLoad
{
[super viewDidLoad];
self.title = @"标准模版";
}
- (void)viewWillDisappear:(BOOL)animated
{
[super viewDidAppear:animated];
}
- (void)viewDidDisappear:(BOOL)animated
{
[super viewDidAppear:animated];
}
- (void)dealloc
{
NSLog(@"%s",__func__);
}
#pragma mark - public Method
#pragma mark - private method
#pragma mark - event response
#pragma mark - UITableViewDelegate
#pragma mark - UITableViewDataSource
//...(多个代理方法依次往下写)
#pragma mark - getters and setters
@end
功能模块名_类别_功能_状态//**<userId*/command+option+/。三个快捷键解决。按需在旁边对方法进行说明解释、返回值、参数的说明和解释 采用 A.B.C 三位数字命名,比如:1.0.2,当有更新的情况下按照下面的依据
版本号示例
A.b.c属于重大内容的更新1.0.2 -> 2.0.0
a.B.c属于小部分内容的更新1.0.2 -> 1.1.1
a.b.C属于补丁更新1.0.2 -> 1.0.3
原文链接:有了这些你们团队的代码肯定规范
]]>Seven times have I despised my soul:
——Kahlil Gibran
The first time when I saw her being meek that she might attain height.
The second time when I saw her limping before the crippled.
The third time when she was given to choose between the hard and the easy, and she chose the easy.
The fourth time when she committed a wrong, and comforted herself that others also commit wrong.
The fifth time when she forbore for weakness, and attributed her patience to strength.
The sixth time when she despised the ugliness of a face, and knew not that it was one of her own masks.
And the seventh time when she sang a song of praise, and deemed it a virtue.
我曾七次鄙视我的灵魂
——卡里.纪伯伦
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。
]]>将一系列代码封装为动态库(dynamic library),并在其中放入描述其接口的头文件,这样做出来的东西就叫框架。有时为iOS平台构建的第三方框架所使用的是静态库(static library),这是因为iOS应用程序不允许在其中包含动态库。这些东西严格来讲并不是真正的框架,然而也经常视为框架。不过,所有iOS平台的系统框架仍然使用动态库。
1 | - (void)enumerateObjectsUsingBlock:(void(^)(id object, NSUInteger idx, BOOL *stop))block |
__bridge
NSCache是线程安全的。而NSDictionary则绝对不具备此优势,意思就是:在开发者自己不编写加锁代码的前提下,多个线程便可以同时访问NSCache。
1 | - (void)p_requestCompleted { |
只要下载请求执行完毕,保留环就解除了,而获取器对象也将会在必要时为系统所回收。
同步块(synchronization block)
1 | - (void)synchronizedMethod { |
NSLock锁对象 NSRecursiveLock递归锁
1 | _lock = [[NSLock alloc] init]; |
缺陷:
1 | _syncQueue = dispatch_queue_create("com.effectiveObjectivec.syncQueue",NULL); |
思路是:把设置操作与获取操作都安排在序列化的队列里执行,这样的话,所有针对属性的访问操作就都同步了。全部加锁任务都在GCD中处理。
并发队列(concurrent queue)
栅栏(barrier)
在队列中,栅栏块必须单独执行,不能与其他块并行。这只对并发队列有意义,因为串行队列中的块总是按顺序逐个来执行的。并发队列如果发现接下来要处理的块是个栅栏块,那么久一直要等栅栏块执行过后,再按正常方式继续向下处理。
dispatch_sync
dispatch_async
dispatch_after
1 | + (id)sharedInstance { |